1.内容介绍
优惠券系统在业务层面承接O2O一小时达业务核心促销,是京东到家营销工具的核心利器,为了支持复杂的业务和高流量的场景,对缓存Redis的应用必不可少。本章内容主要介绍京东到家优惠券系统的架构演化,以及承接高流量的Redis集群实战经验。本文的数据支撑进行了脱敏处理,如有不清晰之处,请见谅。
2.缓存现状
1.数量多
5大缓存集群,缓存支持了约200种业务场景。
2.流量高
集群总内存使用量为T级,QPS高峰期能有每秒千万调用量。
3.场景复杂,IO多
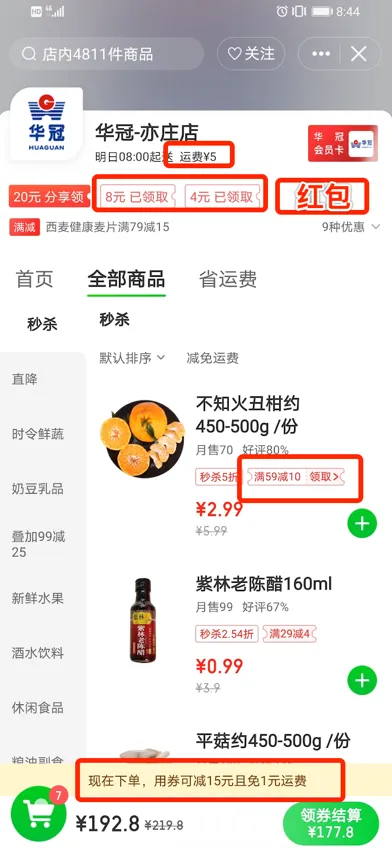
上图为到家门店主页,在门店主页优惠券系统承接5处利益曝光,从上向下分别为:门店运费优惠、门店商品券、红包、商品预估到手价、购物车领券结算,其中有6个优惠券接口承接这5处资源位。介绍下商品预估到手价和购物车领券结算。
预估到手价:承接以商品维度利益优惠,到家平台有商品售卖的地方几乎都承接商品维度的优惠券利益点,涉及商品曝光场景都有预估到手价,调用量50个商品批量调用,能达几百万/分钟调用量,同时优惠券会涉及剩余库存校验、每日领取数量库存校验、总领券数量校验、用户每日领取库存、用户总领取库存,所以优惠券的IO量级比较高。
购物车领券结算:目前该功能为O2O行业最先投入使用,并且用户体验较好。其中图上黄条区域(底部红框的内容)主要是告诉用户购物车当前商品可以使用的优惠,目前主要承载优惠券和运费券优惠提醒,该功能如下图:
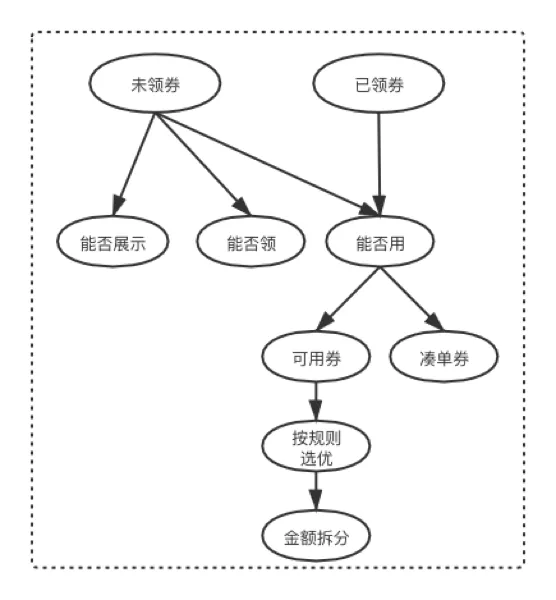
用户已领券50~200张券,未领券大概50~150张券,用户一次请求对应的优惠券自身大概裂变400~1000次网络IO,其中主要列表为券数量以及每张券各种库存校验,大概算一下8次rpc+一张未领券6次io未领券50张+ 1次券信息io用券100张=400多次,按购物车高峰期几十万/每分钟调用量,优惠券领券结算需要承载百万QPS的IO。
综上所述:优惠券是一个高并发、高复杂、大数据量的单体系统。对于这种系统面临许多问题和挑战,为了迎接挑战优惠券进行一系列架构调整,实战部分Redis的也进行一系列优化措施。
3架构演化
随着公司发展扩大,业务的急剧增长以及研发规模的扩大,原有系统已不能满足业务发展的需求,面临着业务需求推进慢、系统性能调优困难、人员耦合问题频现,在此需要降低系统复杂度,进行一系列系统拆分措施。
3.1架构演化-框架介绍
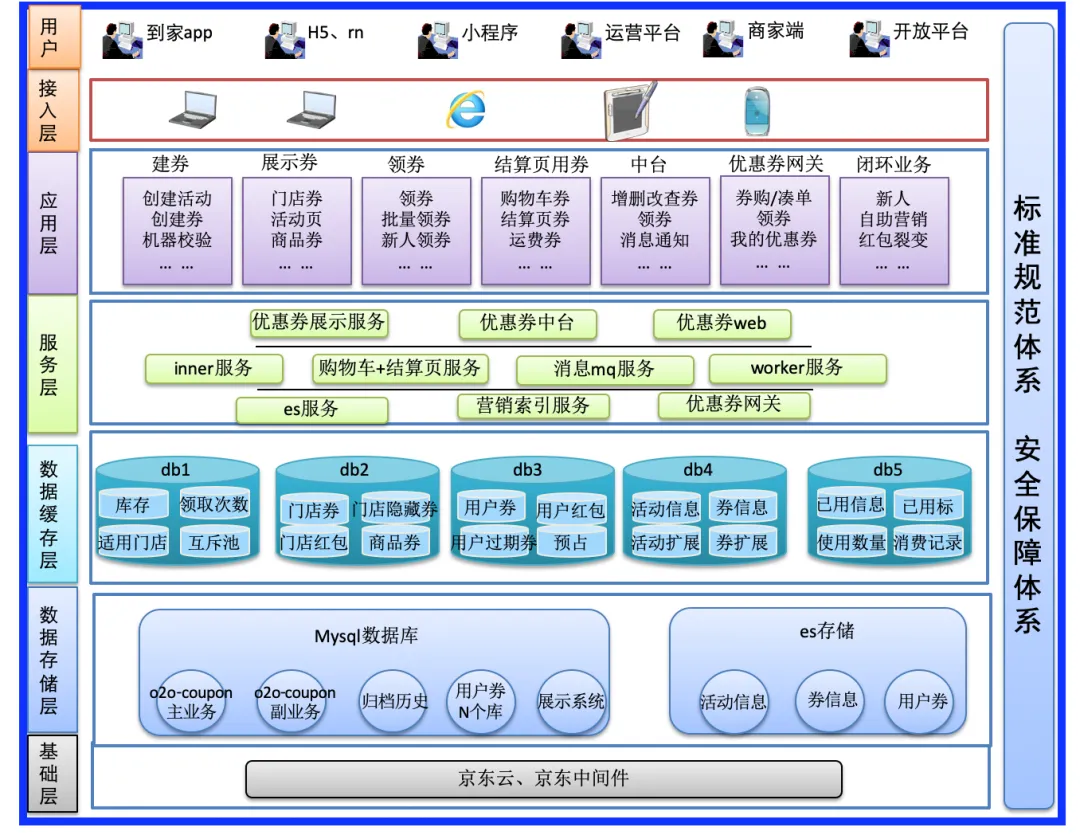
总共分为7层,分别是用户层、接入层、应用层、服务层、数据缓存层、数据存储层、基础层。
应用层:建券、展示券、领券、结算页用券、优惠券中台、优惠券网关、闭环业务。闭环业务(上游业务)是指依赖优惠券中台形成自己独特玩法的上游业务。
服务层:大方便分为B端和C端,C端主要有优惠券展示服务、结算页用券、优惠券网关等;B端主要优惠券中台、建券、领券等。
数据缓存层:5个集群,优惠券打标集群、门店券集群、用户券集群、活动集群、已使用集群。
数据存储层:主要有Mysql和ES进行存储,其中用户下优惠券券数据量比较多,日均亿级的数据体量。
基础层:主要依赖京东私有云体系和京东自研中间件。
3.2架构演化-系统拆分
大部分的系统可以按业务维度进行拆分,足以能解决自己耦合问题,但是优惠券是一个复杂的单体系统,我们一起来看下单体系统我们是如何拆分的。
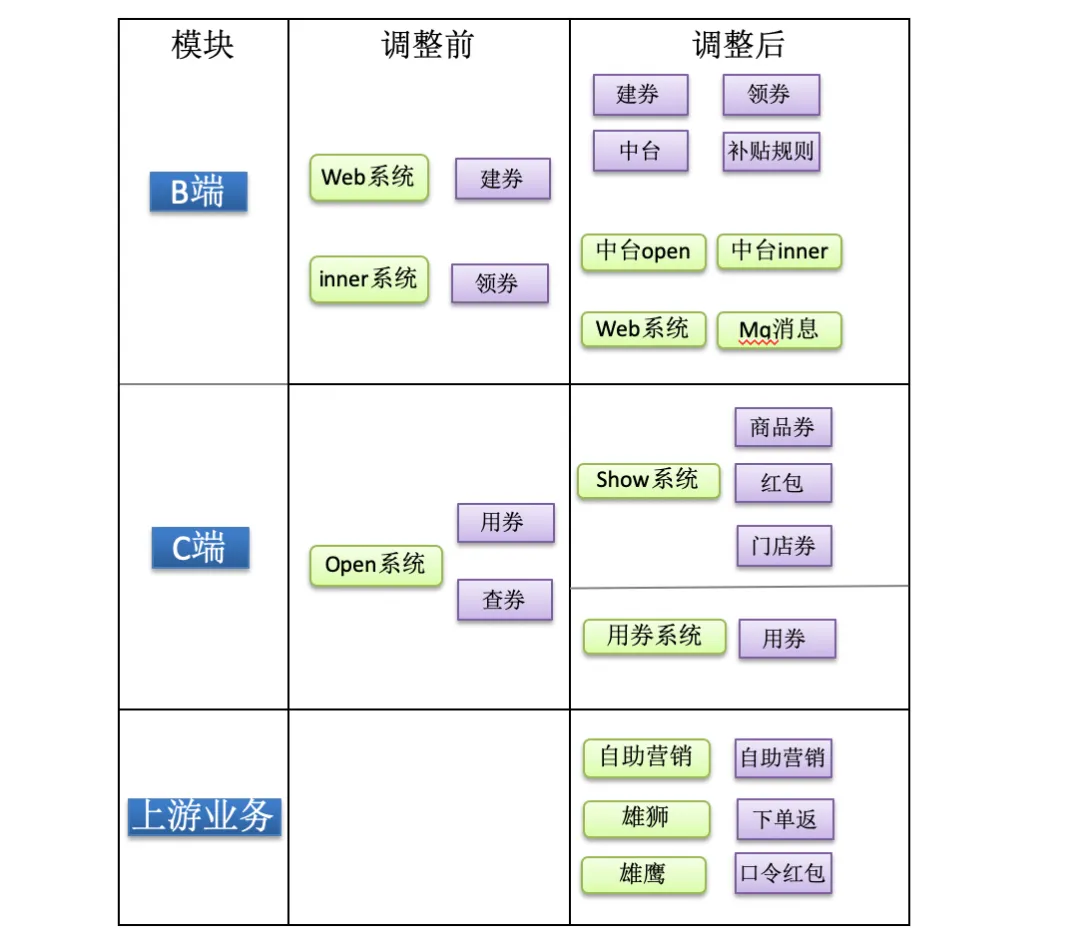
调整前:所有的业务基本分为建券、领券、用券和查券,系统分为open(对C端服务)、inner(对B端服务)、web(运营端)三个项目,随着业务不断发展,带来了一系列问题。
问题描述:1.随着C端机器不断增多扩容,数据库连接数不够。2.高并发场景对核心交易流程用券产生了影响。3.业务、系统、人员耦合在一起,推动需求进度和系统维护带来一定困难。
调整后:将优惠券进行B端、C端、上游业务三个维度进行拆分。
1.C端提供门店券、商品券、红包、以及核心交易流程用券业务;C端系统由原来一个系统拆分为展示系统和用券核心交易流程系统。
2.B端业务分为建券、中台、领券、补贴规则;B端系统形成了中台open(通用对C端服务)、中台inner(通用对B端服务)、WEB(运营端)、MQ消息(将原有分散的消费MQ统一形成一个系统)。
3.闭环业务(上游业务)依赖优惠券中台通用能力实现自有业务独立部署。
4缓存优化
优惠券系统C端使用Redis承接高流量,对Redis的深度了解和学习是优化实战的重要一部分。下面会分别介绍常见的实战优化经验,选取的常用的优化点:大Key、热Key、过期策略。
4.1消灭缓存大Key问题
Redis主线程是单线程模型。大Key表面理解为单个存储Key的Value比较大,参考值:String类型长度大于8000;对于List、Set、Hash、Zset的元素数量大于8000。该数据仅供参考,实际业务不同也可有一定调整。
如果一次操作比较大,会导致主线程处理时间变长,单点阻塞;另外大Key的删除或是过期,也会导致节点阻塞,极端情况会导致主从出现问题,Redis无法响应,所以在使用层面根据业务应拆尽拆。
如果是复杂度比较低的应用,定位大Key是比较简单的事情,通常开发人员根据经验就能定位到,但是优惠券系统有200多缓存Key场景,靠经验值很难定位,针对大Key问题下面拿具体案例进行说明,如何定位、如何解决。
案例背景(优惠券适用门店缓存优化)
1.高峰期响应时长高,所有接口都出现问题。
2.某分片新建连接数飙升、流出量高,并且问题分片每天都变化。
3.定位场景复杂:200多个接口无法确定某个业务;缓存Key和接口之间存在多对多关系。
4.Redis没有慢日志,定位问题困难。
5.大Key存在但是不一定是问题Key;热Key也存在但也不一定是问题,如何找到影响性能具体的Key。
排查过程:
1.根据方法耗时最终可以定位到具体集群,但是不能定位到某个缓存Key,因为Redis是单点阻塞,所以表现为该集群所有缓存都变慢。
2.寻找该集群涉及数据源代码中重复调用过程优化,优化后无效。
3.降级+限流无效。
4.使用主从切换方式定位到问题Key,发现分片流出量从主分片到了从分片。定位到券适用门店缓存,此缓存是CouponId为Key,Value是门店ID,接近上万门店,用来判断券和门店是否适用。
解决方案:
将缓存结构Key是CouponId,Value是适用门店结构,改造为缓存Key是CouponId+门店的维度,B端进行一次写入,C端只判断有没有来做到用户已领取的券在不在该门店展示。
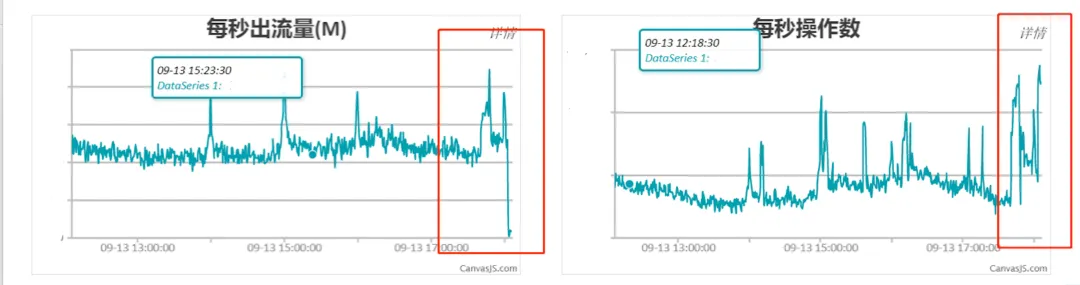
结果:总的每秒流出量由几G/s直接降到几十M/s,单分片由几百M/s降低为几M/s。
总结如何发现大Key:
1.业务经验,假设问题Key。
2.客户端代理,收集大Key信息。
3.查看Redis记录的慢日志。
4.在从集群Scan大Key,以免影响生产环境稳定。
5.读写分离笨办法,对怀疑的Key一个一个进行主从分片切换,观察节点的流出量,这个方法虽然不能快速定位,但是一定能帮助定位到问题。
总结解决大Key:
1.根据业务场景解决,散列足够均匀,足够小。个人认为根据场景解决为首选。
2.对于大Key,要想办法进行业务拆解,无法业务拆分的考虑使用技术手段路由拆分。
3.精简缓存Key的长度,使用缩写替代,例如coupon_info_base改为c_i_b。
4.对字段属性进行精简,使用单字母表示,例如couponName对应存储字母a。
5.数据优先使用整数,比字符串省空间。
6.对缓存数据进行冷热分离,比较热的字段放入一个Key,减少请求的网络流出量。
7.在清理大Key数据时,特别注意不要直接删除,也会造成单点阻塞,使用Scan进行清理。4.0以上引入了unlink,异步删除。
4.2解决缓存热Key问题
Redis单节点可以承受10万+QPS,如果突然有几十万请求访问某一固定Key,那会达到网卡上限,导致节点无法响应。当然这里的量级也是参考值,和实际场景的Key大小和机器性能许多因素都有关系。常见的突出业务场景是秒杀,其他的业务场景也会存在请求量大的热Key,热Key的发现和处理与大Key有些共通之处,也有不一样之处。
热Key发现:
1.业务经验,假设问题Key。
2.抽样抓取请求,这里分为服务端和客户端两个维度抓取,客户端便向集群维度抓取,服务端便向单节点维度抓取。例如:尝试抓10s内的请求然后按请求量对Key排序。
3.Redis自带命令,Redis 4+版本后提供热点Key发现。
4 .查看Redis记录的慢日志。
5.读写分离笨办法,对怀疑的Key一个一个进行主从分片切换,观察节点QPS变化,这个和大Key发现思路一致。
解决热Key:
1.业务优化减少请求量,例如秒杀,网上有各种降流量措施。
2.缓存隔离,减少热Key对其他业务影响。
3.散列多份,放许多份,读取数据时进行随机读取一份,这个方法比较通用。
4.对于热Key前置缓存到应用服务器上,尽量是占用空间小并且不怎么发生变的数据进行前置,不然Gc也是件比较麻烦的事情。
注意:实际生产环境会比较复杂,会存在一些场景比较难以定位。例如:不是大Key也不是热Key,但是会是阻塞节点的主要流量Key。定位方法可以参考读写分离方法,观察节点出流量以及QPS变化。
4.3重视缓存过期策略
实际生产环境经常需要做的是优化Redis的使用空间,减少集群大小,节省成本。经常不增加过期时间,过期时间使用不合理现象。
过期策略是Redis很重要的一部分,了解过期策略有什么好处呢。第一:我们可以学习到一些好的设计思想;第二可以对Redis过期有足够了解,能从原理层知道平时使用Redis应该注意什么。
过期策略:
1.定时删除:插入过期键的同时,开一个定时任务,在键的过期来临时执行删除任务。优点是删除快,对内存友好,但是频繁的执行对CPU不友好。
2.惰性删除:用户查询的时候判断是否过期,过期则删除,用户不查则永远不删除。对CPU友好,对内存不友好。
3.定期删除:每隔一段时间进行一次删除任务,遍历多少个DB,删多少个键由算法决定。一、二的折中,当然如果执行的太频繁,或者每次删除的过多,就跟方式一没什么区别。
Redis是使用了惰性删除和定期删除两种方式。
redisDb结构体:
typedef struct redisDb {
dict *dict;
dict *expires;
...
unsigned long expires_cursor;
} redisDb;Redis数据存储使用redisDb的结构体,其中Dict存储数据,Expires是存储过期时间,不设置过期时间不会存放在Expires中,因此Redis过期策略主要针对Expires进行处理。
惰性删除策略:
int expireIfNeeded(redisDb *db, robj *key) {
if (!keyIsExpired(db,key)) return 0;
if (server.masterhost != NULL) return 1;、
/* Delete the key */
server.stat_expiredkeys++;
propagateExpire(db,key,server.lazyfree_lazy_expire);
notifyKeyspaceEvent(NOTIFY_EXPIRED,
"expired",key,db->id);
int retval = server.lazyfree_lazy_expire ? dbAsyncDelete(db,key) :
dbSyncDelete(db,key);
if (retval) signalModifiedKey(NULL,db,key);
return retval;
}该代码主要体现以下4点:
1.调用ExpireIfNeeded函数进行是否过期判断并删除。
2.如果没过期返回0,如果是从库返回1。
3.如果过期并且是主库,删除返回1。
4.Redis只会从主库删除过期键,主库再同步从库。
这里之前一同事想清理一次过期没删除的数据,问Scan能否触发过期删除?
void scanGenericCommand(client *c, robj *o, unsigned long cursor) {
/* Step 1: 解析 */
/* Step 2: 遍历各种类型集合 */
/* Step 3: 过滤元素 */
while (node) {
...
/* Filter element if it is an expired key. */
if (!filter && o == NULL && expireIfNeeded(c->db, kobj)) filter = 1;
...
node = nextnode;
}
/* Step 4: 回复客户端 */上面一段是Scan大体的4步过程,第一步解析参数,第二步遍历各种类型集合,然后第3步过滤元素中明确调用了ExpireIfNeeded函数进行了惰性删除,所以使用Scan是可以清理过期没删除的数据。第四步回复客户端。
定期删除策略:
#define ACTIVE_EXPIRE_CYCLE_KEYS_PER_LOOP 20 /* 默认每个数据库检测的键数量 Keys for each DB loop. */
#define ACTIVE_EXPIRE_CYCLE_FAST_DURATION 1000 /* 快周期时间 微秒 Microseconds. */
#define ACTIVE_EXPIRE_CYCLE_SLOW_TIME_PERC 25 /* 慢周期最多占用cpu资源 Max % of CPU to use. */
#define ACTIVE_EXPIRE_CYCLE_ACCEPTABLE_STALE 10 /* 可容忍的过期键所占内存比例 % of stale keys after which
we do extra efforts. */
void activeExpireCycle(int type) {
effort = server.active_expire_effort-1, /* Rescale from 0 to 9. */
config_keys_per_loop = ACTIVE_EXPIRE_CYCLE_KEYS_PER_LOOP +
ACTIVE_EXPIRE_CYCLE_KEYS_PER_LOOP/4*effort,
config_cycle_fast_duration = ACTIVE_EXPIRE_CYCLE_FAST_DURATION +
ACTIVE_EXPIRE_CYCLE_FAST_DURATION/4*effort,
config_cycle_slow_time_perc = ACTIVE_EXPIRE_CYCLE_SLOW_TIME_PERC +
2*effort,
config_cycle_acceptable_stale = ACTIVE_EXPIRE_CYCLE_ACCEPTABLE_STALE-
effort;
...
if (type == ACTIVE_EXPIRE_CYCLE_FAST) {
//如果上次不是因为超时而结束,并且当前过期键数量小于可容忍的过期键数量,不处理。
if (!timelimit_exit &&
server.stat_expired_stale_perc < config_cycle_acceptable_stale)
return;
//如果距离上次fast模式的运行时间小于两倍的fast模式的周期,不处理。
if (start < last_fast_cycle + (long long)config_cycle_fast_duration*2)
return;
last_fast_cycle = start;
}
...
timelimit = config_cycle_slow_time_perc*1000000/server.hz/100;
...
if (type == ACTIVE_EXPIRE_CYCLE_FAST)
redisDb *db = server.db+(current_db % server.dbnum);
//循环db
for (j = 0; j < dbs_per_call && timelimit_exit == 0; j++) {
do {
...
while (sampled < num && checked_buckets < max_buckets) {
for (int table = 0; table < 2; table++) {
if (table == 1 && !dictIsRehashing(db->expires)) break;
unsigned long idx = db->expires_cursor;//当前db过期游标开始检测。
idx &= db->expires->ht[table].sizemask;
dictEntry *de = db->expires->ht[table].table[idx];
while(de) {
...
ttl = dictGetSignedIntegerVal(e)-now;
//操作过期删除
if (activeExpireCycleTryExpire(db,e,now)) expired++;
if (ttl > 0) {
ttl_sum += ttl;
ttl_samples++;
}
sampled++;
}
}
db->expires_cursor++;
}
...
//每循环16次,看下执行时间和超时时间,如果超时跳出结束
if ((iteration & 0xf) == 0) { /* check once every 16 iterations. */
elapsed = ustime()-start;
if (elapsed > timelimit) {
timelimit_exit = 1;
server.stat_expired_time_cap_reached_count++;
break;
}
}
//如果已清理的过期键*100/所有检索的键>可容忍过期键所占比内存
} while (sampled == 0 ||
(expired*100/sampled) > config_cycle_acceptable_stale);
}
...
double current_perc;
if (total_sampled) {
current_perc = (double)total_expired/total_sampled;
} else
current_perc = 0;
//动态变化
server.stat_expired_stale_perc = (current_perc*0.05)+
(server.stat_expired_stale_perc*0.95);
}以上源码有省略,只选取核心逻辑,定期删除主要是调用activeExpireCycle函数:
1.两个地方调用,一个是server.c/databasesCron()函数,每100ms执行一次,一个是server.c/beforeSleep()函数,在redis的事件主循环中,每次循环都会执行一次。
2.activeExpireCycle两种模式:快周期和慢周期。
常量说明:
1.ACTIVE_EXPIRE_CYCLE_KEYS_PER_LOOP默认每个数据库检测键数量。
2.ACTIVE_EXPIRE_CYCLE_FAST_DURATION 快周期,1000us。
3.ACTIVE_EXPIRE_CYCLE_SLOW_TIME_PERC慢周期多占用CPU时间25%。
4.ACTIVE_EXPIRE_CYCLE_ACCEPTABLE_STALE可容忍的过期键所占内存比例10%。
5.Effort调节速度, Effort越大,CPU负担越重,所以根据自己的需要设置effort的值。
6.server.active_expire_effort默认1。
删除过程:
1.For循环DB。
2.Do while循环进行容忍度校验,如果已清理的过期键*100/所有检索的键>可容忍过期键所占比内存,一直循环。
跳出条件:每循环16次,看下执行时间和超时时间,如果超时跳出结束。
慢周期25ms,快周期1000us。
db->expires_cursor当前db过期游标开始检测。每次执行都是根据全局游标接着上次位置进行。6.0新版本才有该游标。
activeExpireCycleTryExpire操作删除。
3.server.stat_expired_stale_perc = (current perc0.05)+(server.stat_expired_stale_perc0.95),动态变化,在此体现了activeExpireCycle使用的是自适应算法。
总结:
1.activeExpireCycle函数使用的是自适应算法。
2.过期 Key 最好不要太密集,每次检测会耗尽分配的时间片,达到可接受的密度比例,对Key过期时间设置进行一定的随机,减少集中过期影响CPU。
3.db->expires_cursor 6.0才有。4.0是随机20个Key。
4.业务使用时尽量都设置过期时间。
5.使用Scan触发惰性删除操作,非高峰期扫描主节点。
