分布式压测
使用JMeter做大并发压力测试的场景下,单机受限与内存、CPU、网络IO,会出现服务器压力还没有上去,但是压测机压力太大已经死机!为了让JMeter拥有更强大的负载能力,JMeter提供分布式压测能力。
- 单机网络带宽有限
- 高延时场景下,单机可模拟最大线程数有限
如下是分布式压测架构:
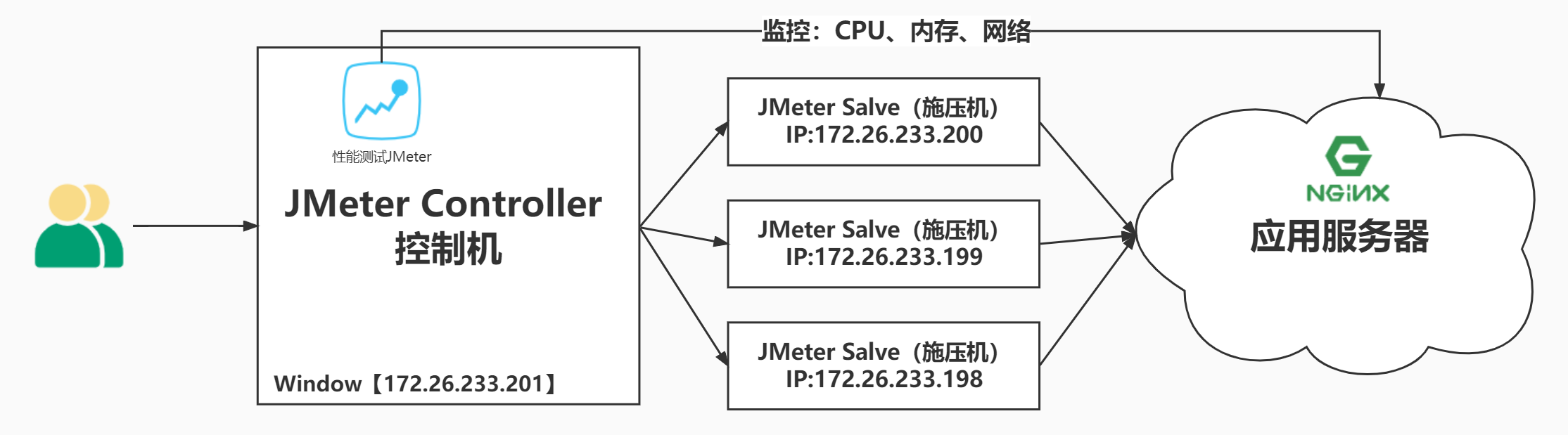
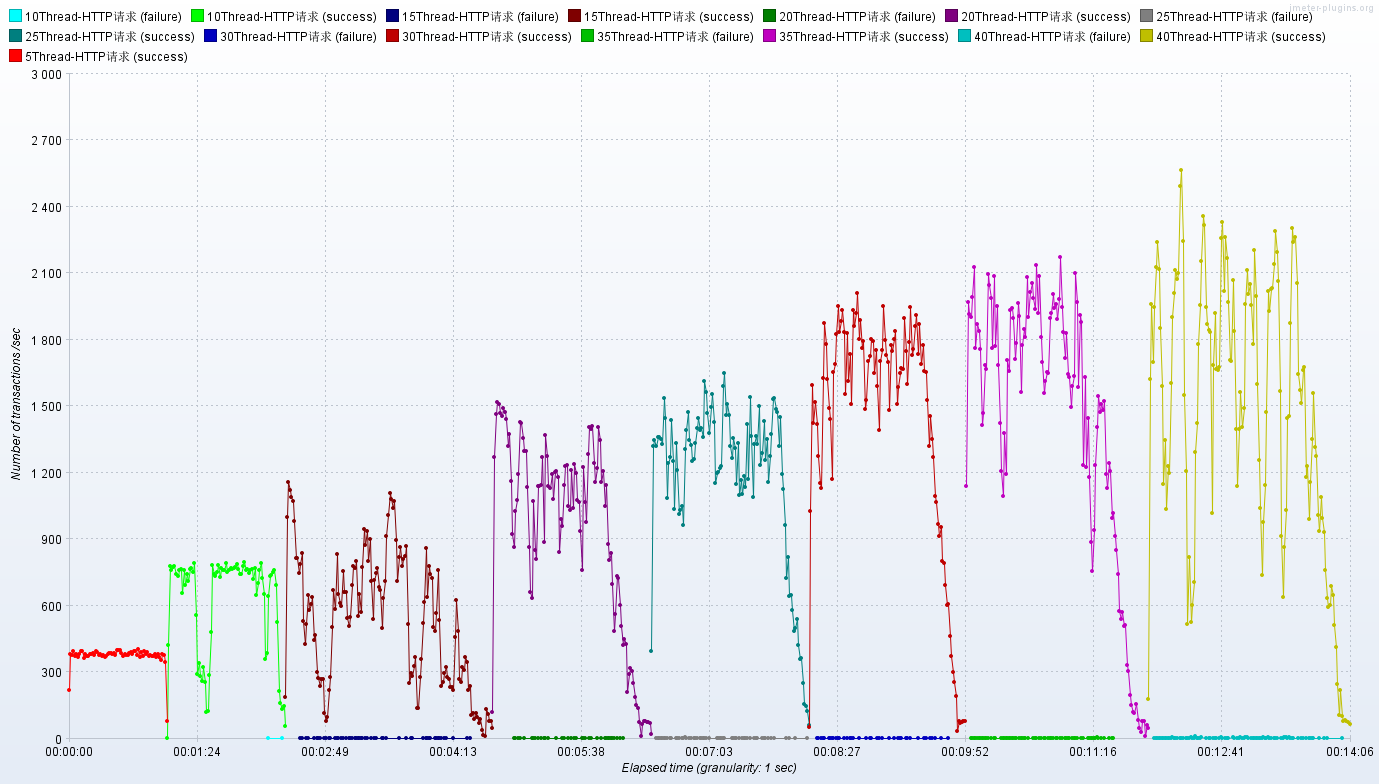
注意:在JMeter Master节点配置线程数10,循环100次【共1000次请求样本】。如果有3台Salve 节点。那么Master启动压测后,每台Salve都会对被测服务发起10x100次请求。因此,压测产生的总样本
数量是:10 x 100 x 3 = 3000次。
搭建JMeter Master控制机和JMeter Salve施压机
- 第一步:三台JMeter Salve搭建在Linux【Centos7】环境下
- 第二步:JMeter Master搭建在Windows Server环境下【当然也可以搭建在Linux里面,这里用win是为了方便观看】
搭建注意事项:
- 需保证Salve和Server都在一个网络中。如果在多网卡环境内,则需要保证启动的网卡都在一个网段。
- 需保证Server和Salve之间的时间是同步的。
- 需在内网配置JMeter主从通信端口【1个固定,1个随机】,简单的配置方式就是关闭防火墙,但存在安全隐患。
Linux部署JMeter Salve
(1)下载安装
wget https://archive.apache.org/dist/jmeter/binaries/apache-jmeter-5.4.1.tgz
tar -zxvf apache-jmeter-5.4.1.tgz
mv apache-jmeter-5.4.1 ./apache-jmeter-5.4.1-salve(2)配置修改rmi主机hostname
# 1.改ip
vim jmeter-server
# RMI_HOST_DEF=-Djava.rmi.server.hostname=本机ip
# 2.改端口
vim jmeter.properties
# RMI port to be used by the server (must start rmiregistry with same port)
server_port=1099
# To change the default port (1099) used to access the server:
server.rmi.port=1098(3)配置关闭server.rmi.ssl
# Set this if you don't want to use SSL for RMI
server.rmi.ssl.disable=true(4)启动jmeter-server服务
nohup ./jmeter-server > ./jmeter.out 2>&1 &分布式环境配置
(1)确保JMeter Master和Salve安装正确。
(2)Salve启动,并监听1099端口。
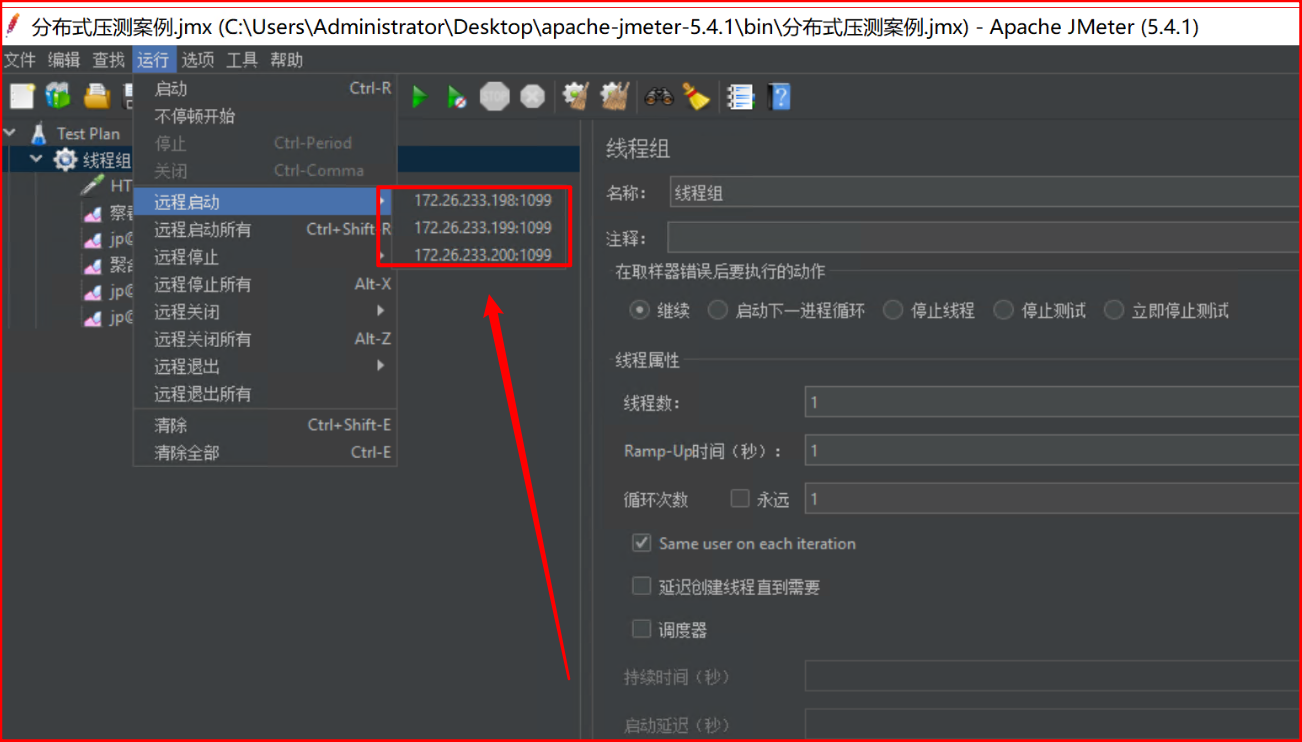
(3)在JMeter Master机器安装目录bin下,找到jmeter.properties文件,修改远程主机选项,添加3个Salve服务器的地址。
remote_hosts=172.17.187.78:1099,172.17.187.79:1099,172.17.187.81:1099(4)启动jmeter,如果是多网卡模式需要指定IP地址启动
jmeter -Djava.rmi.server.hostname=172.17.187.82(5)验证分布式环境是否搭建成功:
服务容器优化
Tomcat调优
为什么对SpringBoot嵌入式的Tomcat进行调优?
基于应用性能瓶颈分析得出结论,当响应时间比较长时,系统瓶颈主要存在与Tomcat中!
系统异常率较高,与Tomcat内部IO模型有关系【多线程&网络编程】
问题:可不可以基于RT与TPS算出服务端并发线程数?
服务端线程数计算公式:TPS/ (1000ms/ RT均值)
调优:嵌入式Tomcat配置
Springboot开发的服务使用嵌入式的Tomcat服务器,那么Tomcat配置使用的是默认配置,我们需要对Tomcat配置进行适当的优化,让Tomcat性能大幅提升。
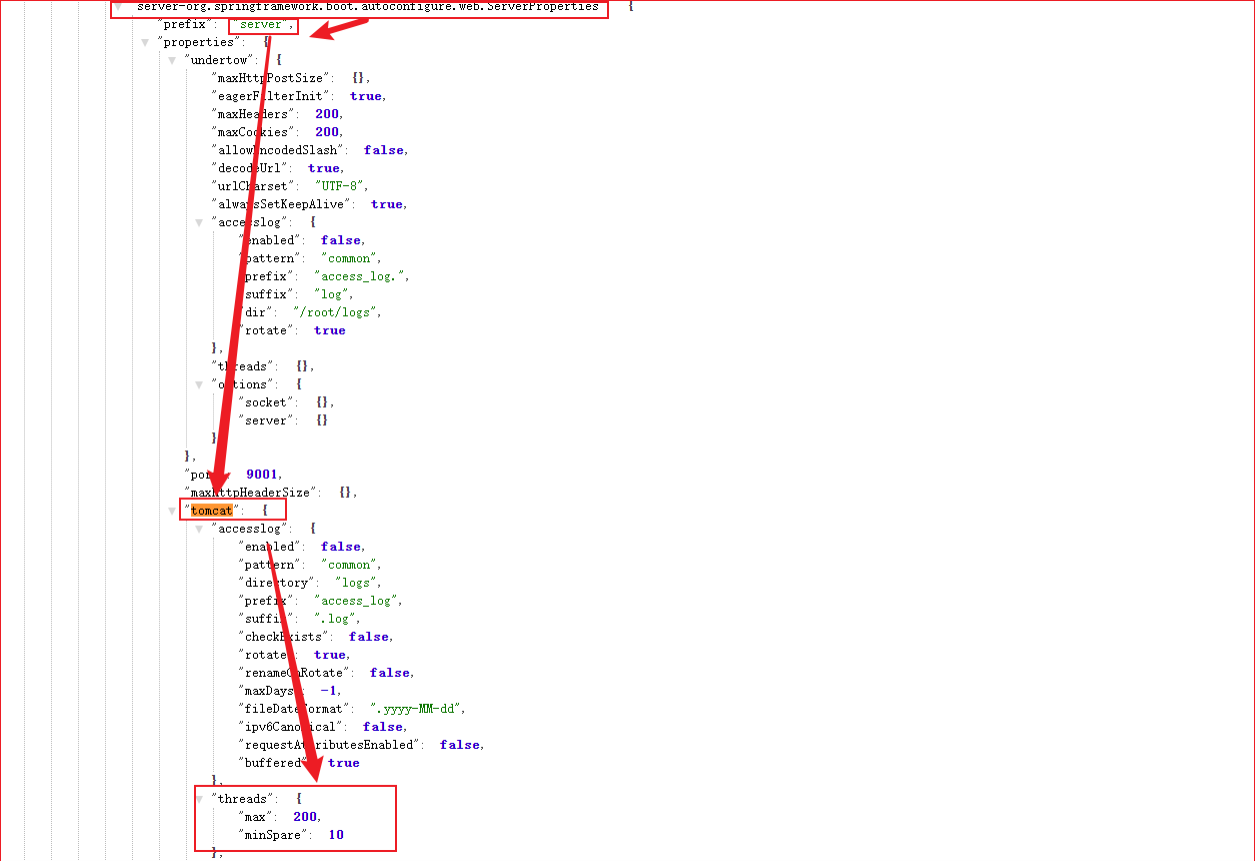
修改配置如下所示:可以使用外挂配置,也可以修改配置文件application.yml。
注意,做了任何修改一定要确认配置生效,否则干的再久也是白搭!
# Tomcat的maxConnections、maxThreads、acceptCount三大配置,分别表示最大连接数,最大
线程数、最大的等待数,可以通过application.yml配置文件来改变这个三个值,一个标准的示例如
下:
server.tomcat.uri-encoding: UTF-8
# 思考问题:一台服务器配置多少线程合适?
server.tomcat.accept-count: 1000 # 等待队列最多允许1000个请求在队列中等待
server.tomcat.max-connections: 20000 # 最大允许20000个链接被建立
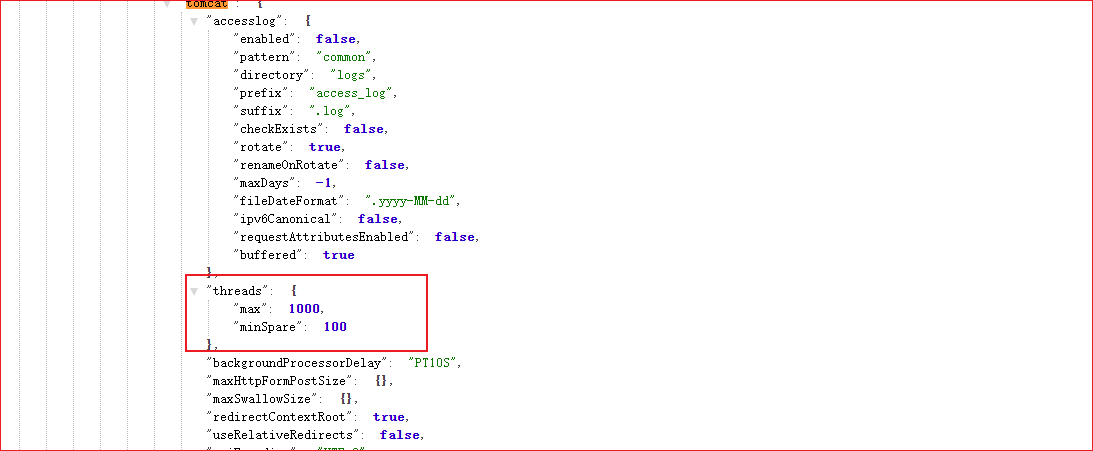
## 最大工作线程数,默认200, 4核8g内存,线程数经验值800
server.tomcat.threads.max: 800 # 并发处理创建的最大的线程数量
server.tomcat.threads.min-spare: 100 # 最大空闲连接数,防止突发流量
# 暴露所有的监控点
management.endpoints.web.exposure.include: ''
# 定义Actuator访问路径
management.endpoints.web.base-path: /actuator
# 开启endpoint 关闭服务功能
management.endpoint.shutdown.enabled: true1)maxThreads:最大线程数
- 每一次HTTP请求到达Web服务,Tomcat都会创建一个线程来处理该请求。
- 最大线程数决定了Web服务容器可以同时处理多少个请求,默认值是200。
最大线程数并不是越大越好!
- 最大线程数只是TPS的影响因素之一,还不是最关键的哪个。
- 增加线程是有成本的,不能无限制增大。线程过多不仅仅会带来线程上下文切换的成本,而且线程
- 也需要消耗内存资源。
- JVM默认Xss堆栈大小1M
那么最大线程数的值应该设置多少合适呢?
- 这个需要基于业务系统的监控结果来定。RT均值很低,可以不用设置,RT均值很高,可以考虑加线程数
- 当然,如果接口响应时间低于100毫秒,足以产生足够的TPS。系统瓶颈不在于此,则不建议设置最大线程数。
- 我个人的最大线程数设置的经验值为:
- 1C2G,线程数200
- 4C8G,线程数800
2)accept-count:最大等待连接数
当调用HTTP请求数达到Tomcat的最大线程数时,还有新的请求进来,这时Tomcat会将该剩余请
求放到等待队列中
acceptCount就是指队列能够接受的最大的等待连接数
默认值是100,如果等待队列超了,新的请求会被拒绝(connection refused)
3)Max Connections:最大连接数
- 最大连接数是指在同一时间内,Tomcat能够接受的最大连接数。如果设置为-1,则表示不限制
- 默认值:
- 对BIO模式,默认值是Max Threads;如果使用定制的Executor执行器,哪默认值将是执行器中Max Threads的值。
- 对NIO模式,Max Connections 默认值是10000
- Max Connections和accept-count关系:
- 当连接数达到最大值Max Connections后系统会继续接收连接,但不会超过acceptCount限制
注意:在做优化的时候,一定要确定你的修改是生效【JVM、Tomcat、OpenResty…】
调优配置生效确认
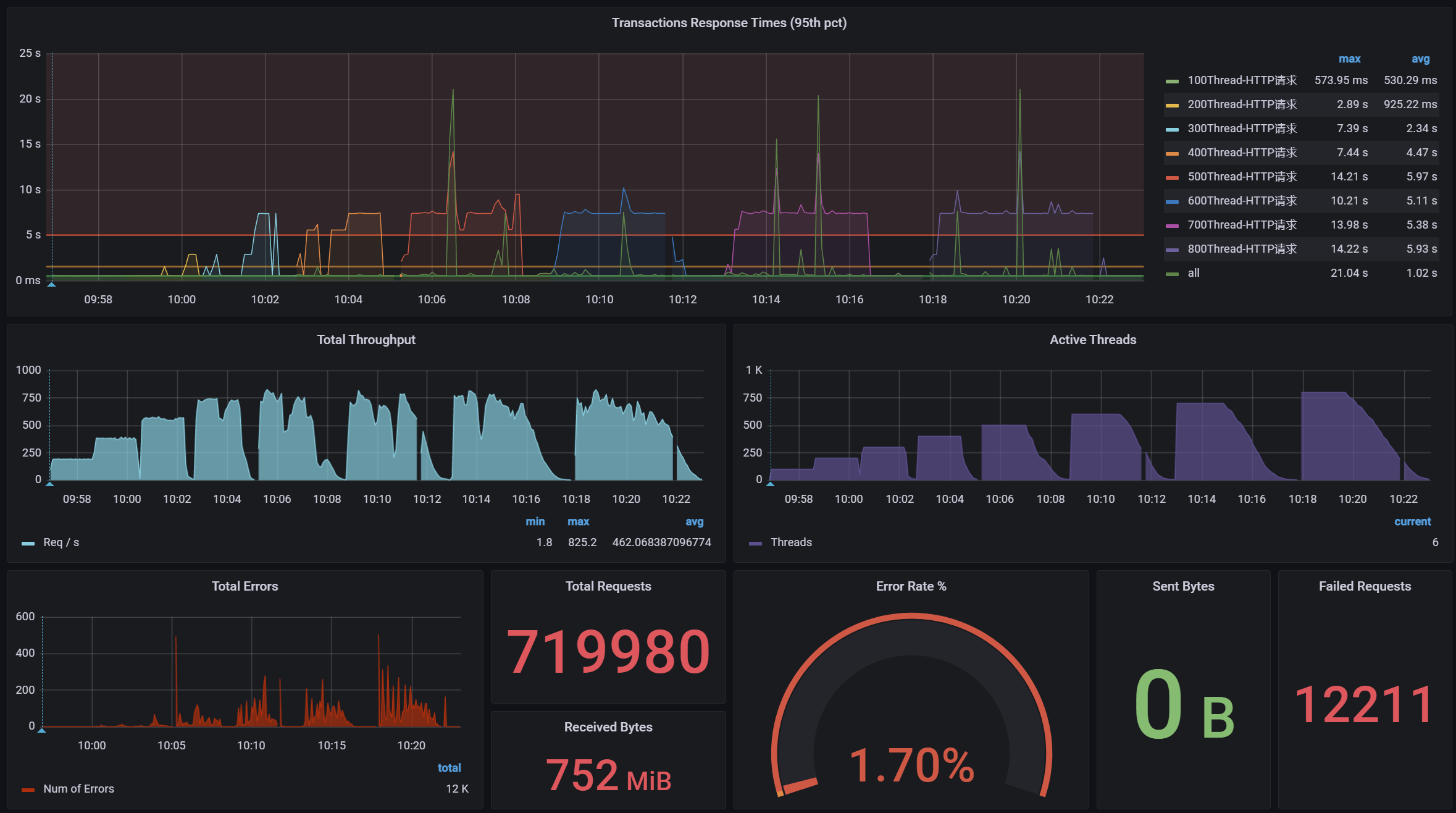
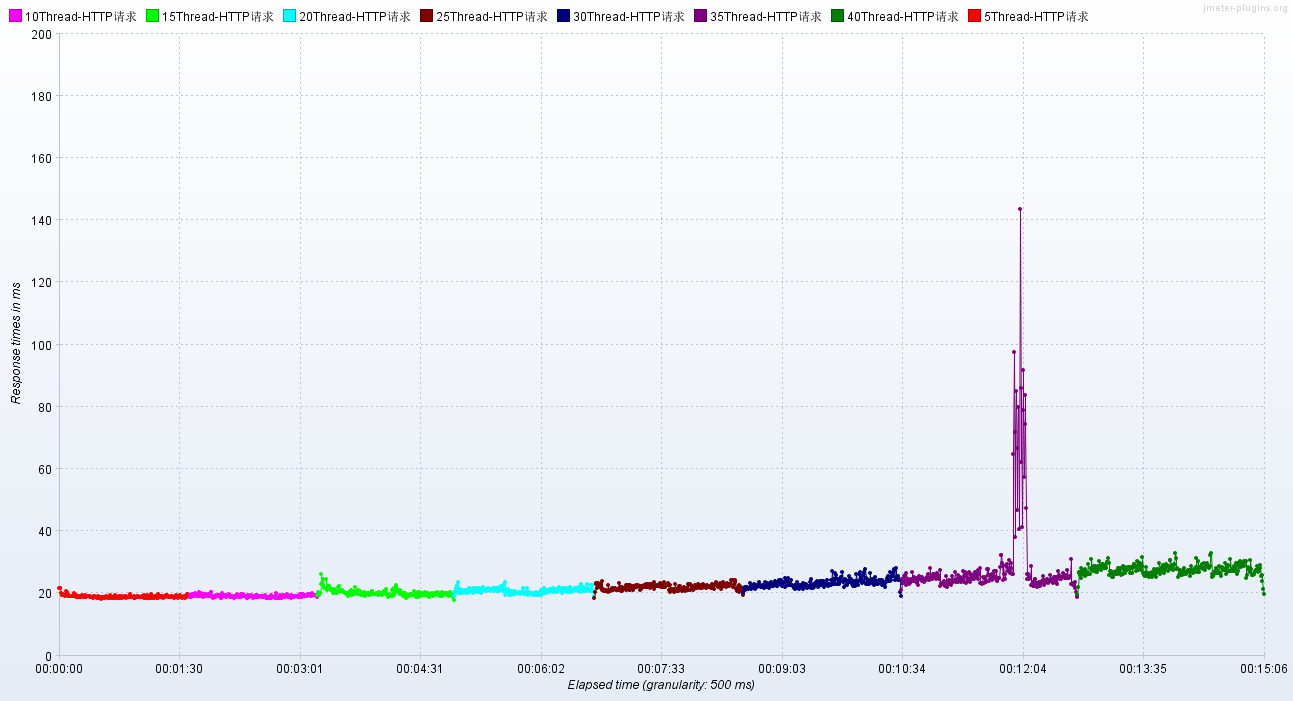
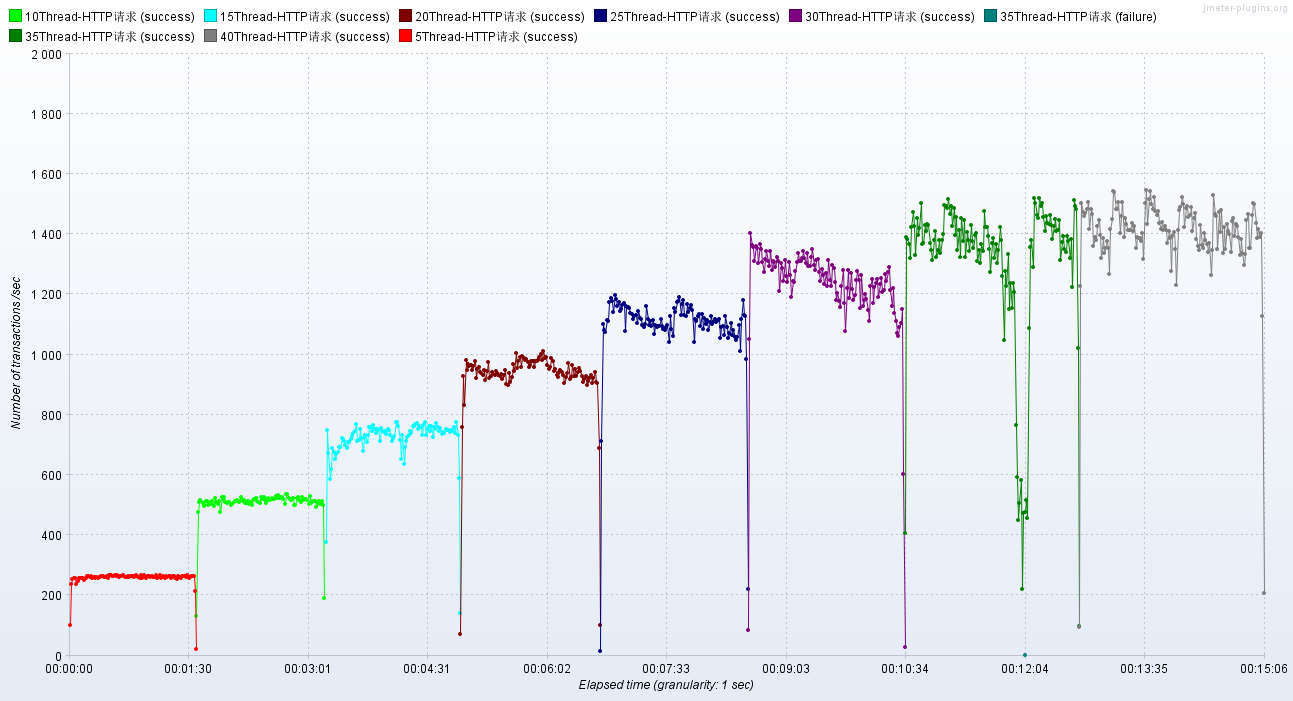
调优前后的性能对比
调优前:压力机Active,RT、TPS、系统进程运行状态【应用活动线程数】

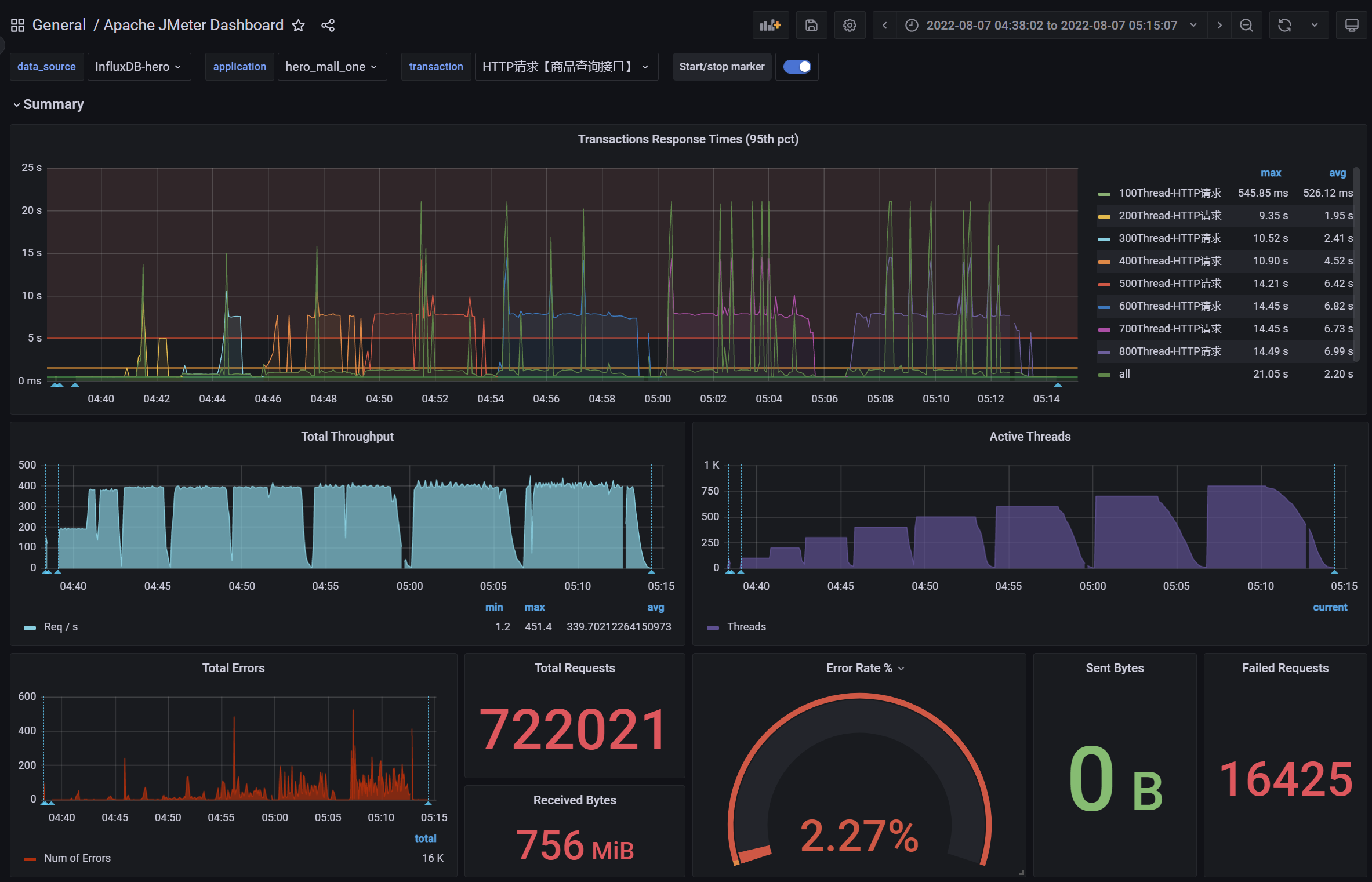
调优后:压力机Active,RT、TPS、系统进程运行状态【应用活动线程数】

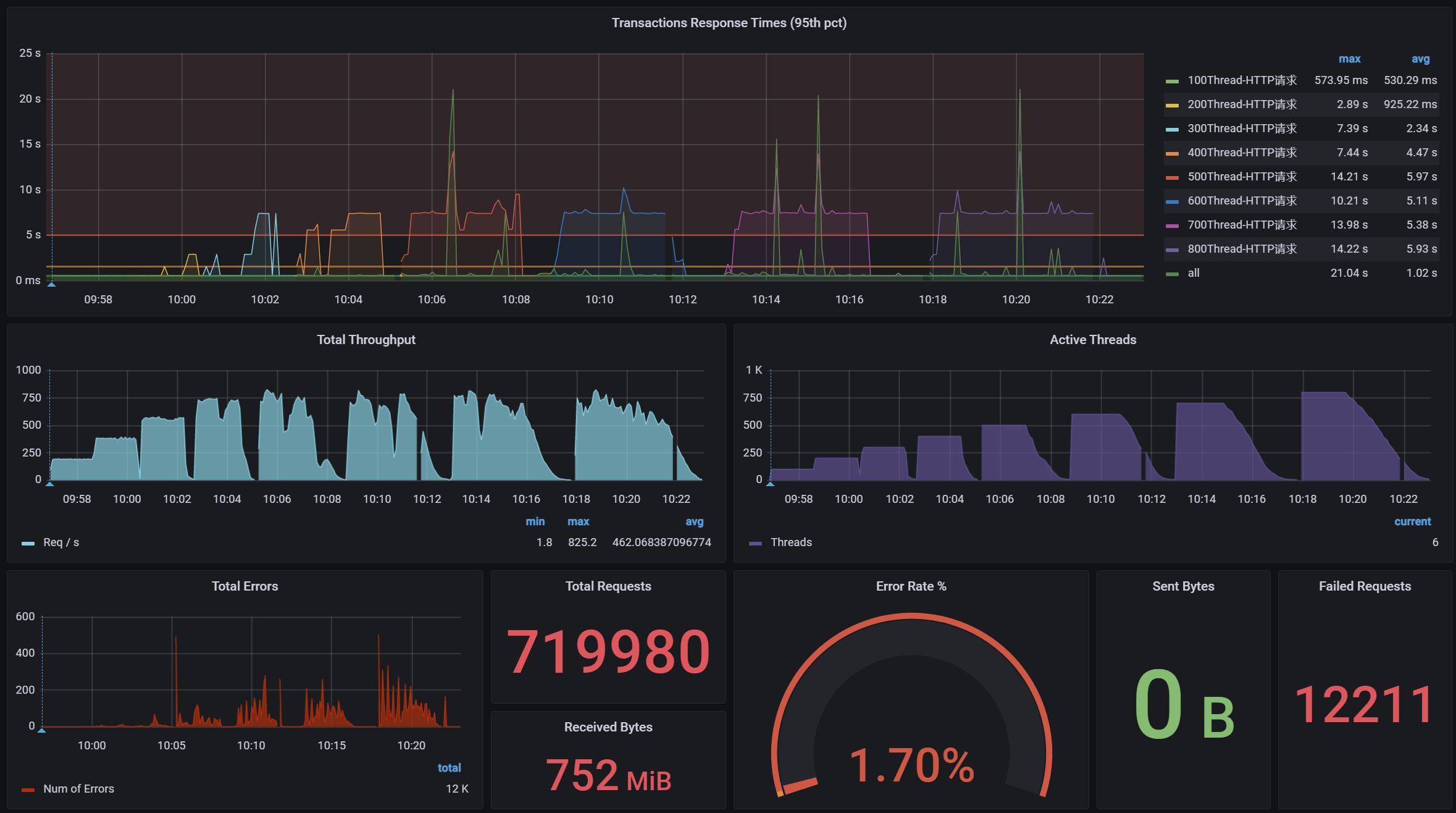
结论:提升Tomcat最大线程数,在高负载场景下,TPS提升接近1倍,同时RT大幅降低;
网络IO模型调优
IO模型介绍

众所周知文件读写性能是影响应用程序性能的关键因素之一。NIO与原来的IO有同样的作用和目的,但是使用的方式完全不同,NIO支持面向缓冲区的、基于通道的IO操作。NIO以更加高效的方式进行文件的读写操作。
Java的NIO【new io】是从Java 1.4版本开始引入的一套新的IO API用于替代标准的Java IO API。
JDK1.7之后,Java对NIO再次进行了极大的改进,增强了对文件处理和文件系统特性的支持。我们称之为AIO,也可以叫NIO2。
优化:使用NIO2的Http协议实现,对请求连接器进行改写。
结论:可以发现服务响应时间大幅缩短,并且稳定
@Configuration
public class TomcatConfig {
//自定义SpringBoot嵌入式Tomcat
@Bean
public TomcatServletWebServerFactory servletContainer() {
TomcatServletWebServerFactory tomcat = new
TomcatServletWebServerFactory() {};
tomcat.addAdditionalTomcatConnectors(http11Nio2Connector());
return tomcat;
}
//配置连接器nio2
public Connector http11Nio2Connector() {
Connector connector=new
Connector("org.apache.coyote.http11.Http11Nio2Protocol");
Http11Nio2Protocol nio2Protocol = (Http11Nio2Protocol)
connector.getProtocolHandler();
//等待队列最多允许1000个线程在队列中等待
nio2Protocol.setAcceptCount(1000);
// 设置最大线程数
nio2Protocol.setMaxThreads(1000);
// 设置最大连接数
nio2Protocol.setMaxConnections(20000);
//定制化keepalivetimeout,设置30秒内没有请求则服务端自动断开keepalive链接
nio2Protocol.setKeepAliveTimeout(30000);
//当客户端发送超过10000个请求则自动断开keepalive链接
nio2Protocol.setMaxKeepAliveRequests(10000);
// 请求方式
connector.setScheme("http");
connector.setPort(9003); //自定义的端口,与源端口9001可以共用,知识改了连接器而已
connector.setRedirectPort(8443);
return connector;
}
}调优前后的性能对比
调优前:RT、TPS

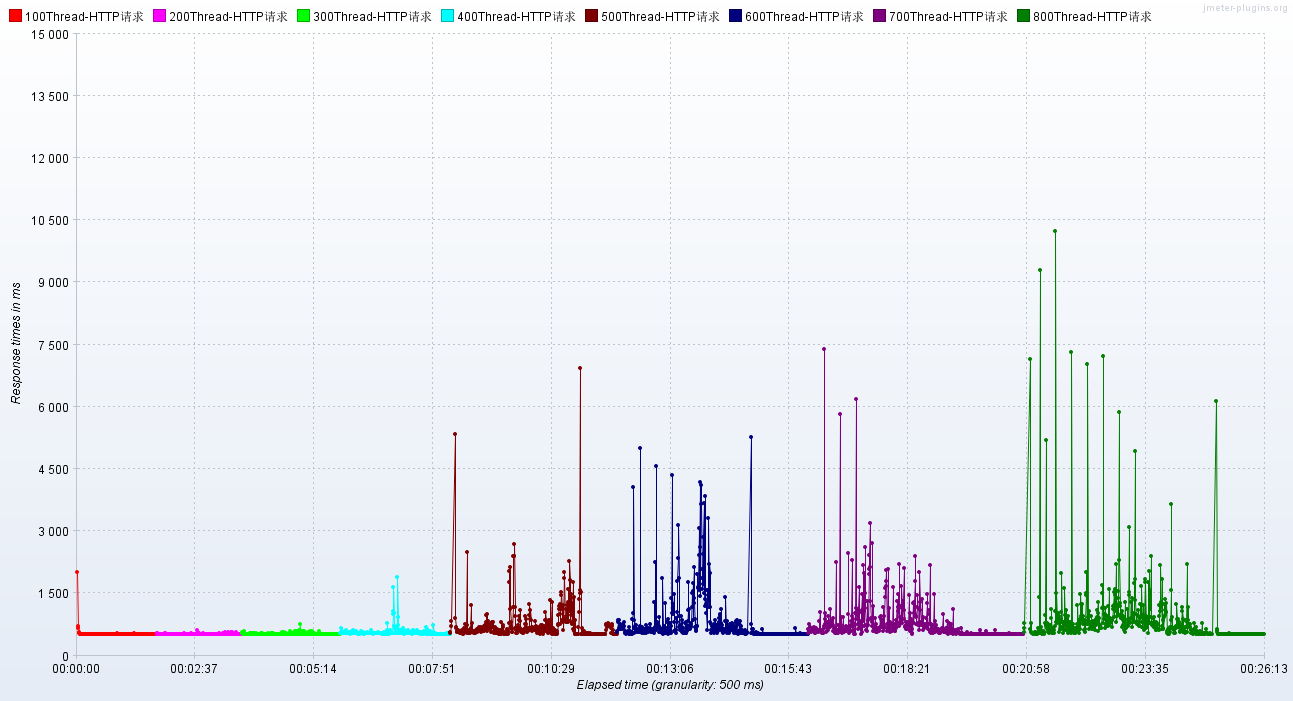
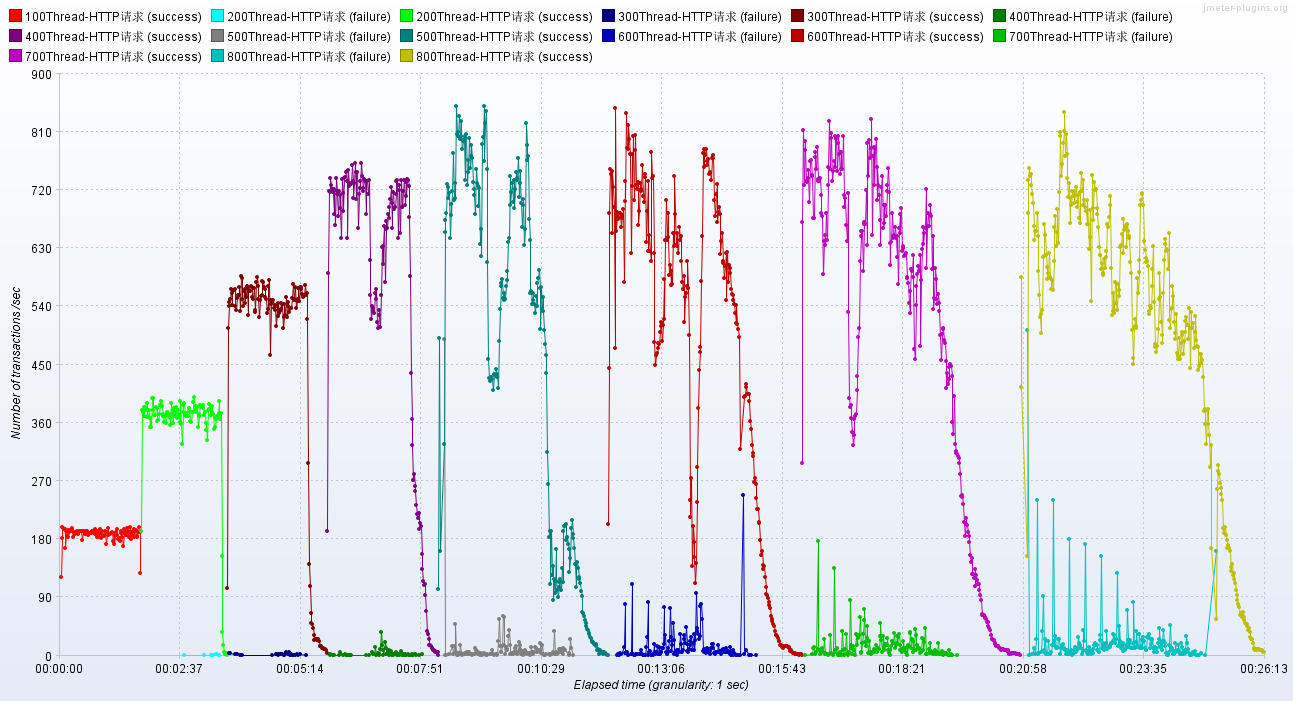
调优后:RT、TPS

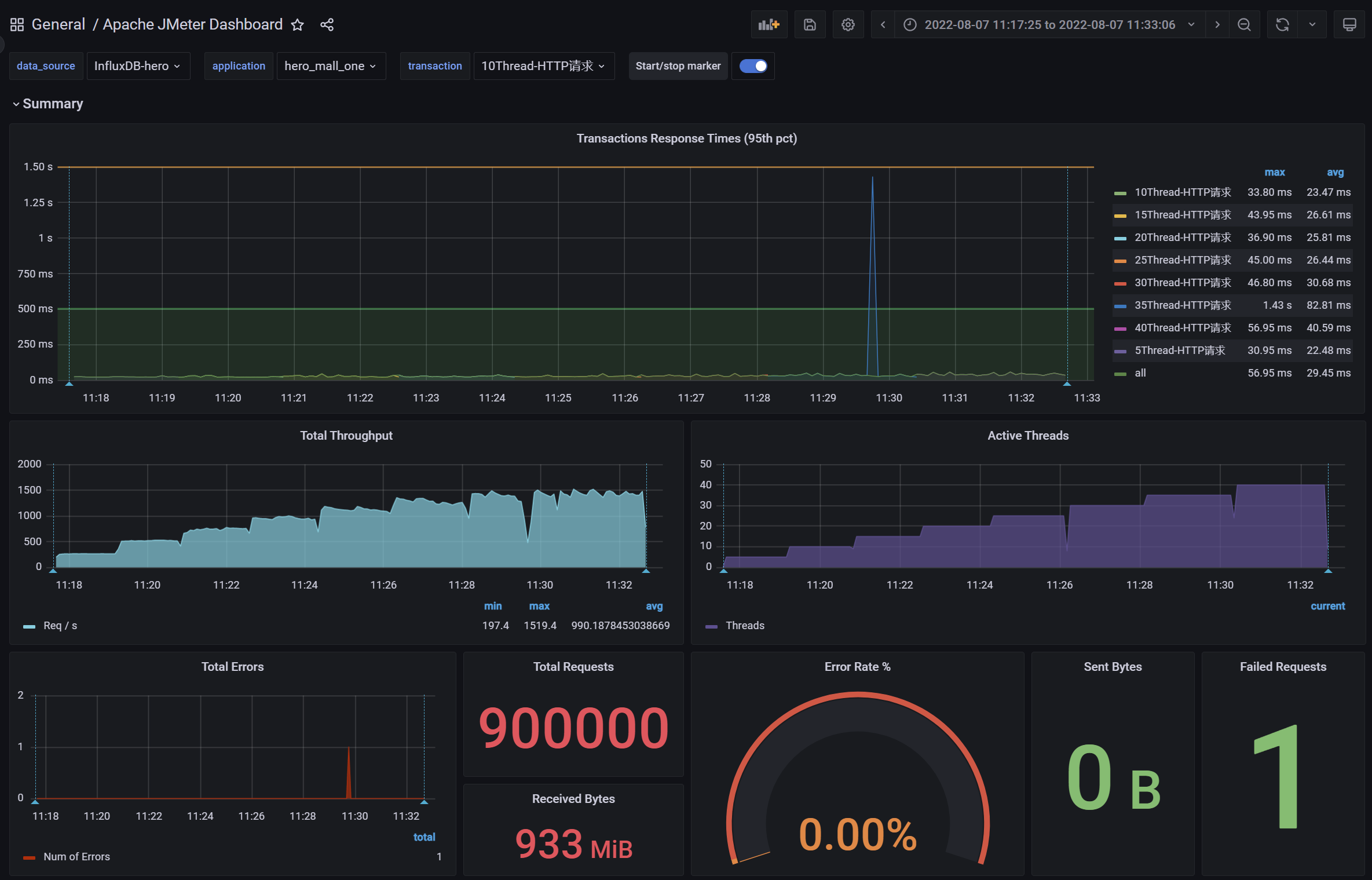
小结:将NIO升级为AIO之后,RT的毛刺大幅降低,异常数(超时3s)几乎为0。
容器优化Tomcat升级Undertow
Undertow是一个用Java编写的灵活的高性能Web服务器,提供基于NIO的阻塞和非阻塞API。
- 支持Http协议
- 支持Http2协议
- 支持Web Socket
- 最高支持到Servlet4.0
- 支持嵌入式
SpringBoot的web环境中默认使用Tomcat作为内置服务器,其实SpringBoot提供了另外2种内置的服务器供我们选择,我们可以很方便的进行切换。
- Undertow红帽公司开发的一款基于 NIO 的高性能 Web 嵌入式服务器 。轻量级Servlet服务器,比Tomcat更轻量级没有可视化操作界面,没有其他的类似jsp的功能,只专注于服务器部署,因此undertow服务器性能略好于Tomcat服务器;
- Jetty开源的Servlet容器,它是Java的web容器。为JSP和servlet提供运行环境。Jetty也是使用Java语言编写的。
配置操作过程:
在spring-boot-starter-web排除tomcat
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> <exclusions> <exclusion> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-tomcat</artifactId> </exclusion> </exclusions> </dependency>导入其他容器的starter
<!--导入undertow容器依赖--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-undertow</artifactId> </dependency>配置
# 设置IO线程数, 它主要执行非阻塞的任务,它们会负责多个连接 server.undertow.threads.io: 800 # 阻塞任务线程池, 当执行类似servlet请求阻塞IO操作, undertow会从这个线程池中取得线程 # 默认值是IO线程数8 server.undertow.threads.worker: 8000 # 以下的配置会影响buffer,这些buffer会用于服务器连接的IO操作,有点类似netty的池化内存管理 # 每块buffer的空间大小越小,空间就被利用的越充分,不要设置太大,以免影响其他应用,合适即可 server.undertow.buffer-size: 1024 # 每个区分配的buffer数量 , 所以pool的大小是buffer-size buffers-per-region # 是否分配的直接内存(NIO直接分配的堆外内存) server.undertow.direct-buffers: true压测
调优前后的性能对比
调优前:RT、TPS【这个是没有进行NIO2优化的Tomcat】

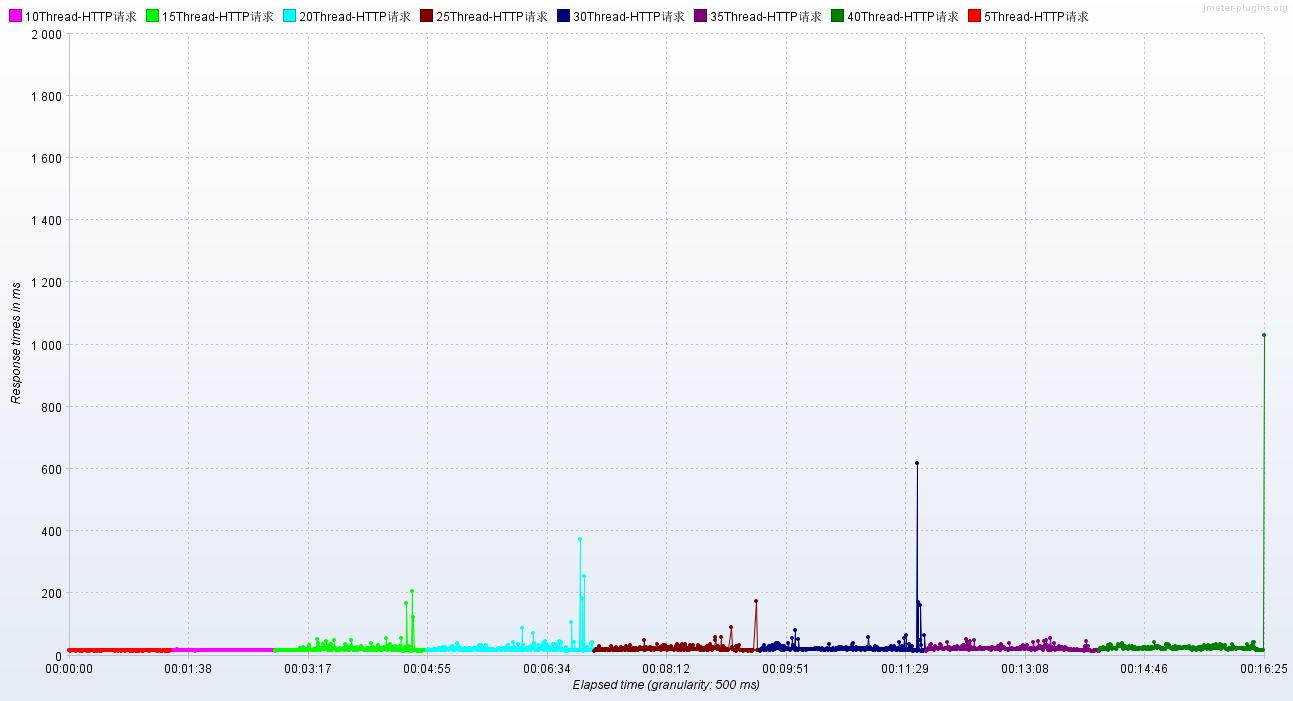
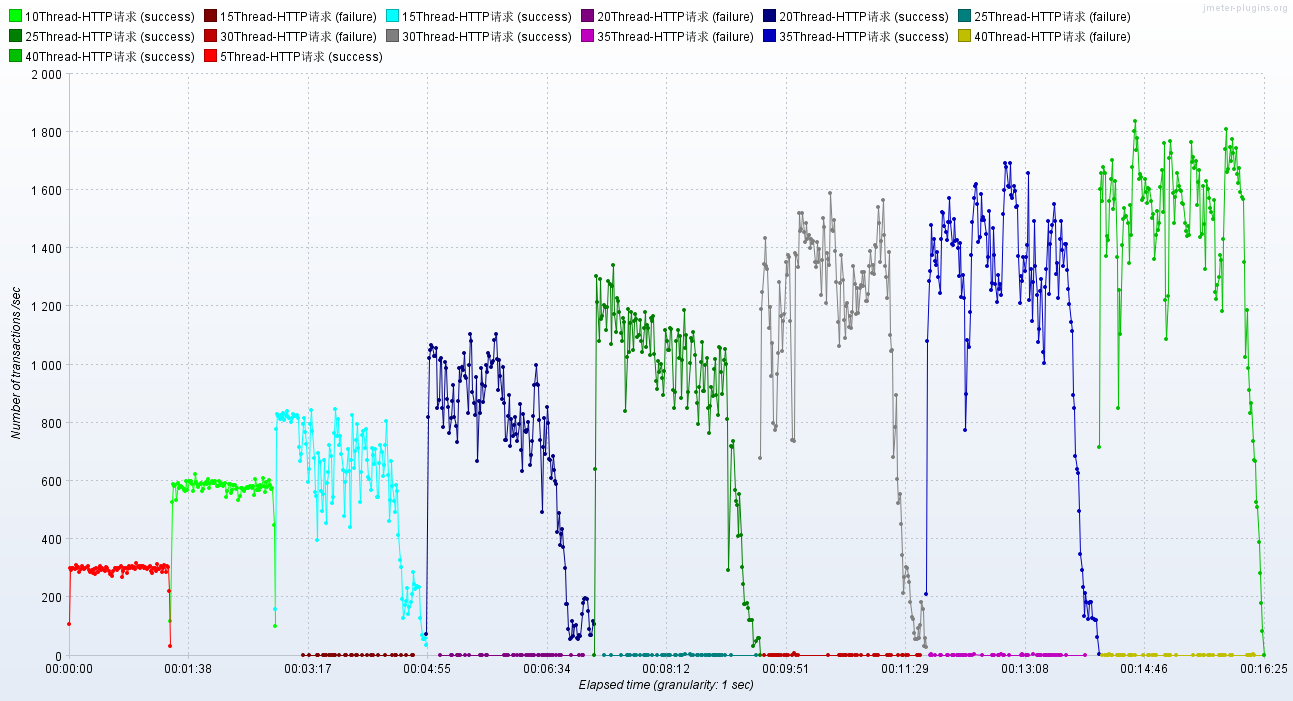
调优后:RT、TPS

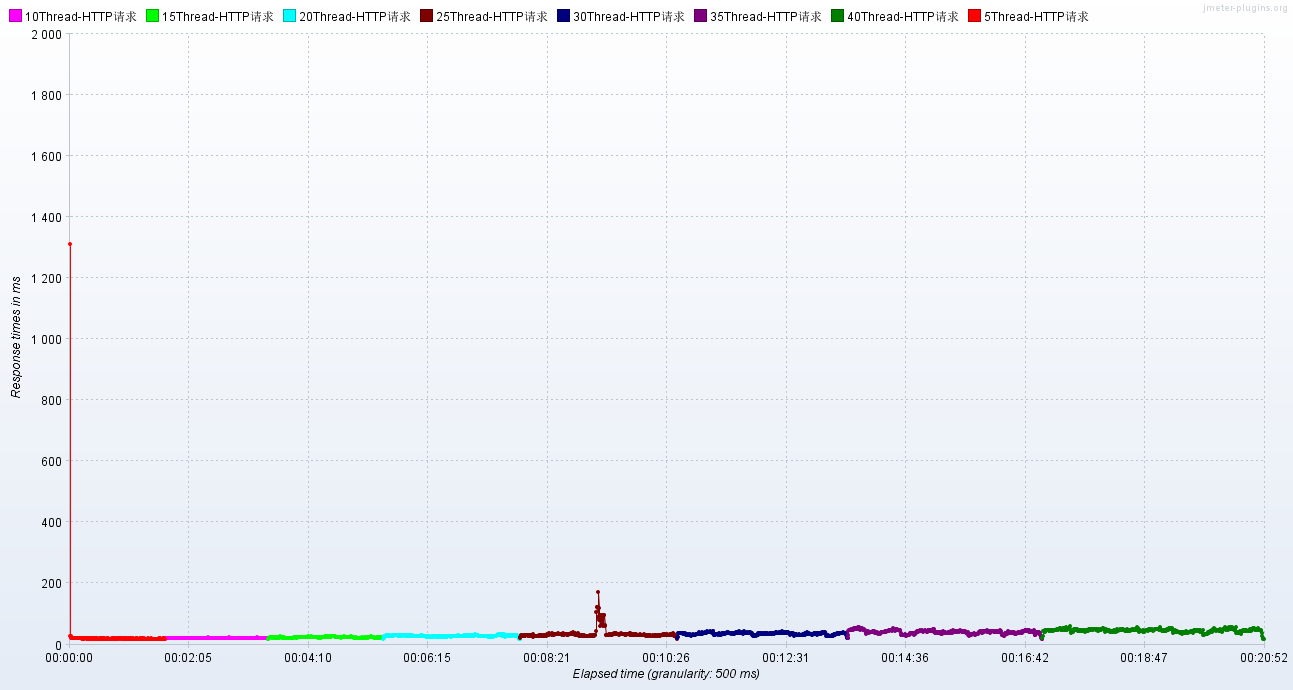
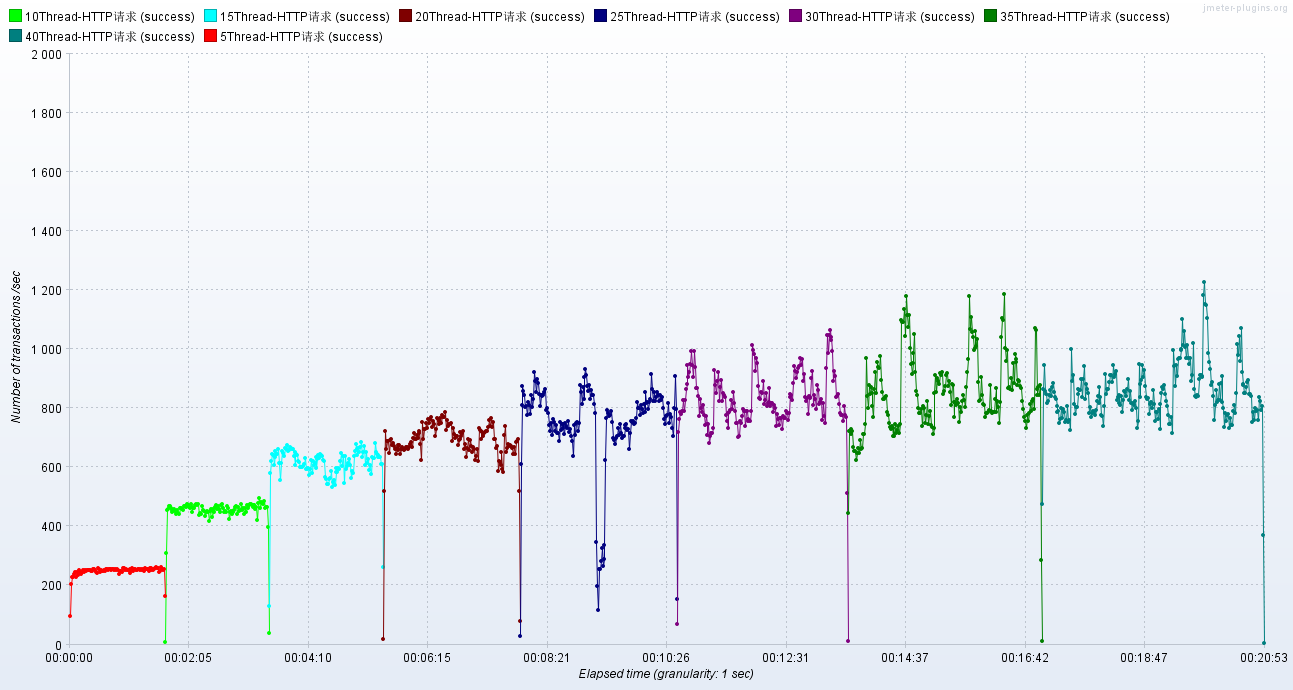
小结:
- 更换了服务容器之后,RT更加平稳,TPS的增长趋势更平稳,异常数(超时3s)几乎为0。
- 在低延时情况下,接口通吐量不及Tomcat。
- 稳定压倒一切,如果只是写json接口,且对接口响应稳定性要求高,可以选用Undertow
还有很多可以优化的空间就不一一举例,这里我们更多的是教大家分析应用性能问题的方法,最直观的
感受应用性能到底卡在什么地方。虽然算不上很全面,但是作为高级开发工程师,到这个程度就够了。
其他可以优化的地方:
- ARP-IO模型
- Jetty 容器
- KeepAliveTimeout【默认】
- MaxKeepAliveRequests
数据库调优
这两条SQL语句有什么区别呢?
# SQL01 - 效率更好
select id from tb_sku where name='华为 HUAWEI 麦芒7 6G+64G 魅海蓝 全网通 前置智慧双摄 移动联通电信4G手机 双卡双待';
# SQL02 - 效率更好
select id from tb_sku where spu_id=10000018913700;为什么要进行MySQL数据库调优?
响应时间打下去,最重要的在数据库!
- 提升网站整体通吐量,优化用户体验数据库是关键之一
- 流畅页面的访问速度,良好的网站功能体验
- 避免网站页面出现访问错误
- 由于数据库连接timeout产生页面5xx错误
- 由于慢查询造成页面无法加载
- 由于阻塞造成数据无法提交
- 增加数据库的稳定性:很多数据库问题都是由于低效的查询引起的
什么影响数据库性能?
- 服务器: OS、CPU、Memory、Network
- MySQL :
- 数据库表结构【对性能影响最大】
- 低下效率的SQL语句
- 超大的表
- 大事务
- 数据库配置
- 数据库整体架构
数据库调优到底调什么?
- 优化SQL语句调:根据需求创建结构良好的SQL语句【实现同一个需求,SQL语句写法很多】
- 数据库表结构调优:索引,主键,外键,多表关系等等
- MySQL配置调优:最大连接数,连接超时,线程缓存,查询缓存,排序缓存,连接查询缓存等等
- 服务器硬件优化:多核CPU、更大内存
为什么使用索引就能加快查询速度呢?
场景一:面试官问你,有没有做过数据库优化呀,我来问你一个特别简单的问题:查询的时候有没有给查询字段加过索引?为什么要加,加上之后怎么就会变快呢?请您简单描述一下原因
- 索引就是事先排好顺序,从而在查询的时候可以使用二分法等高效率的算法查找
- 除了索引查找,就是一般顺序查找,这两者的差异是数量级的差异。
- 二分法查找的时间复杂度是O(log n),而一般顺序查找的时间复杂度是O(n)
- 索引的数据结构是B+树,是一种比二分法查找时间复杂度更好的数据结构
数据库优化是一个很大的话题,里面涉及数据库架构,事务,索引,锁…等原理。这个部分要想弄明白,得铺垫很多底层理论,这里就不展开了。
绝大多数小伙伴并不能正确的使用索引!
- 全值匹配我最爱,最左前缀要遵守;
- 带头大哥不能死,中间兄弟不能断;
- 索引列上不计算,范围之后全失效;
- Like百分写最右,覆盖索引不写星;
- 不等空值还有OR,索引失效要少用。
OpenResty调优
OpenResty是一个基于 Nginx 与 Lua 的高性能 Web 平台,其内部集成了大量精良的 Lua 库、第三方模块以及大多数的依赖项。用于方便地搭建能够处理超高并发、扩展性极高的动态 Web 应用、Web 服务和动态网关。OpenResty的目标是让你的Web服务直接跑在 Nginx 服务内部,充分利用 Nginx 的非阻塞 I/O 模型,不仅仅对 HTTP 客户端请求,甚至于对远程后端诸如 MySQL、PostgreSQL、Memcached以及 Redis 等都进行一致的高性能响应。
什么是Nginx?
Nginx是一款轻量级的Web 服务器/反向代理服务器及电子邮件(IMAP/POP3)代理服务器,在BSD-like 协议下发行。其特点是占有内存少,并发能力强,事实上nginx的并发能力在同类型的网页服务器中表现较好,中国大陆使用nginx网站用户有:百度、京东、新浪、网易、腾讯、淘宝等。
安装OpenResty到Linux服务器
配置域名映射
访问主机名映射配置:

压测配置
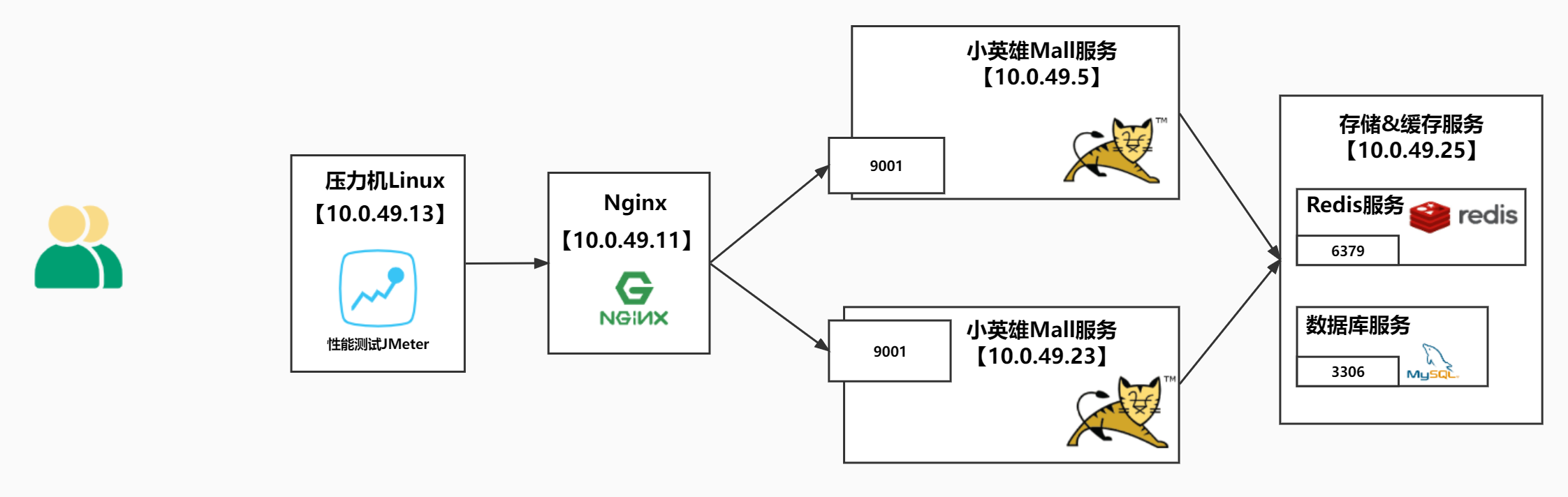


# 指定你要代理的tomcat服务器列表
upstream hero-server{
# 内网ip:端口号
server 172.17.187.78:9003;
server 172.17.187.79:9003;
}
server {
listen 80;
server_name hero01;
location / {
# 反向代理小英雄服务集群
proxy_pass http://hero-server;
}
}测试结果
JMeter:聚合报告、TPS、RT

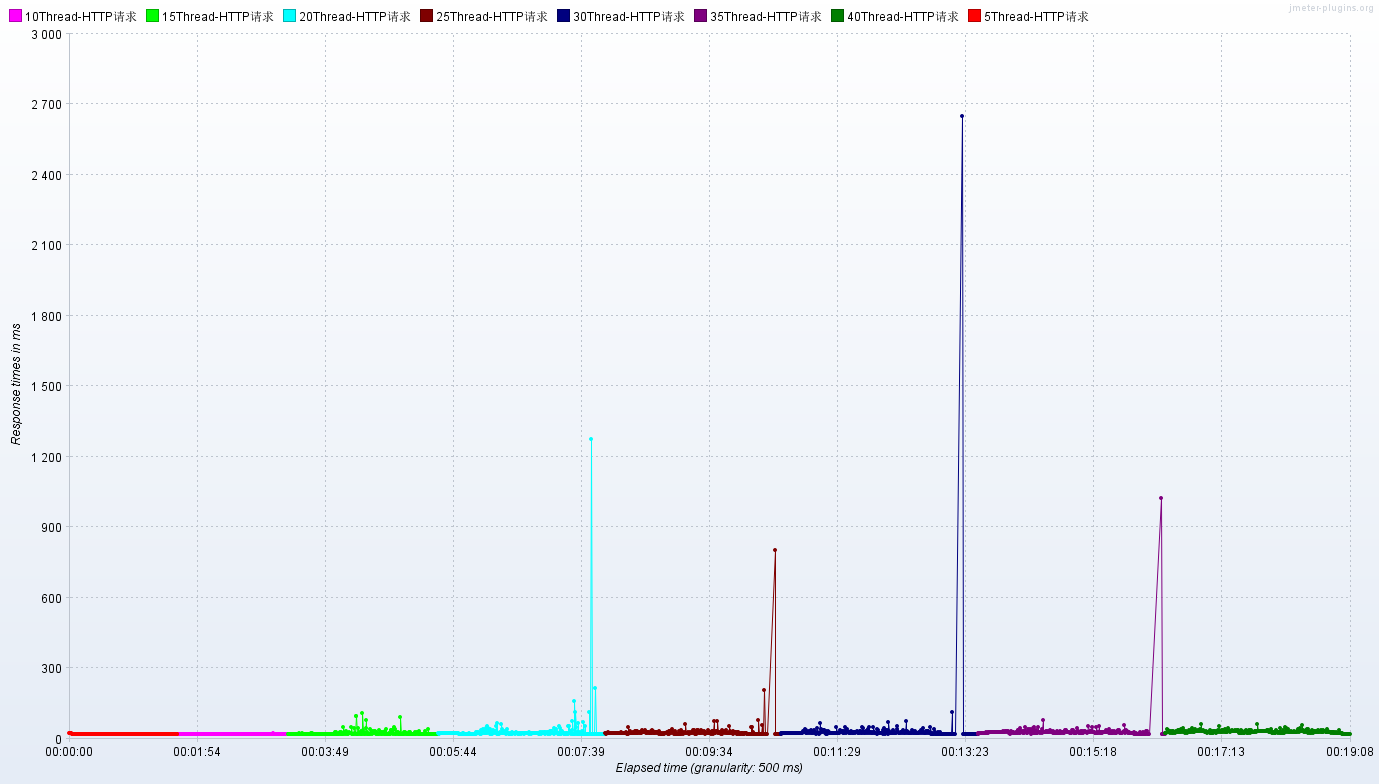
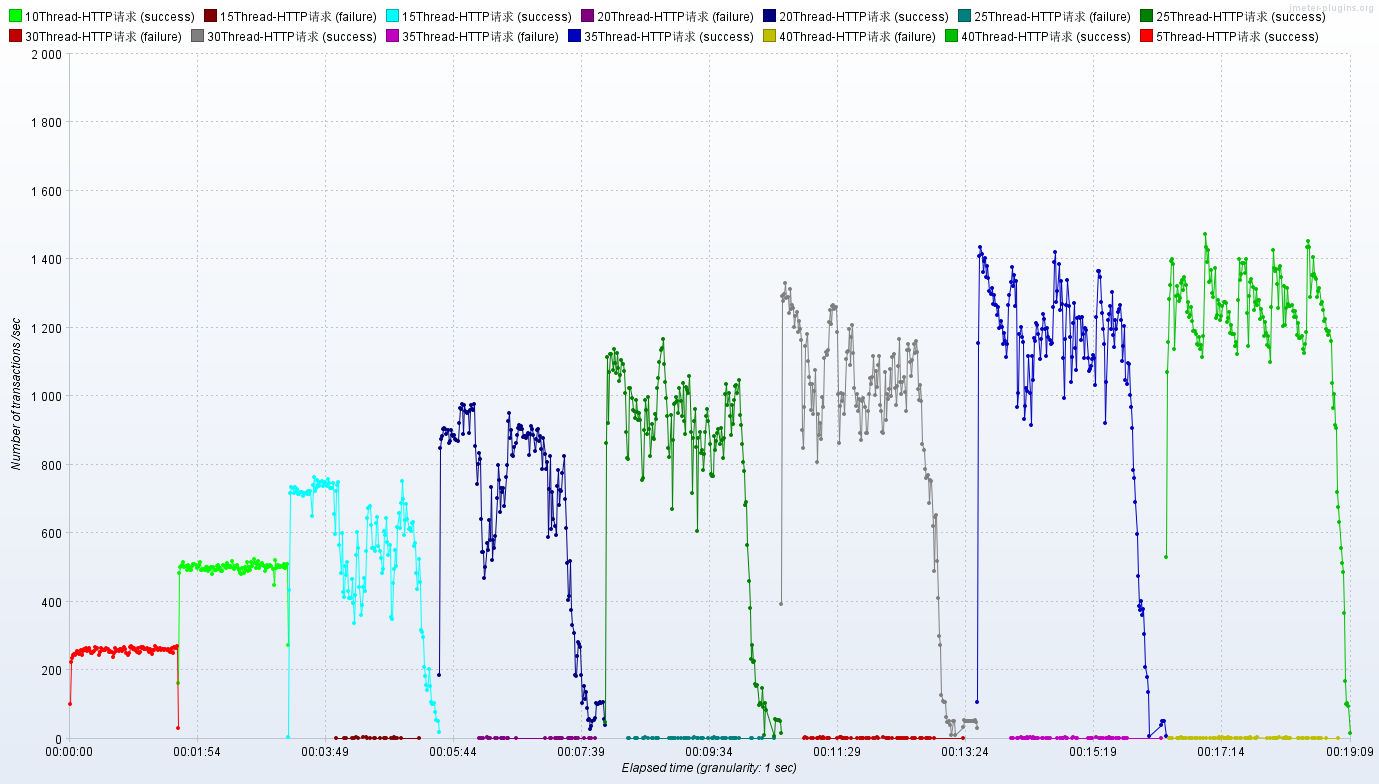
Nginx-CPU、内存、网络
- 资料:压力测试\07-低延时20ms-Nginx
数据库服务-CPU、内存、网络
- 资料:压力测试\07-低延时20ms-Nginx
小英雄服务-CPU、内存、网络
- 资料:压力测试\07-低延时20ms-Nginx
小结:使用了OpenResty反向代理了服务,TPS会在原有的基础上再翻倍!
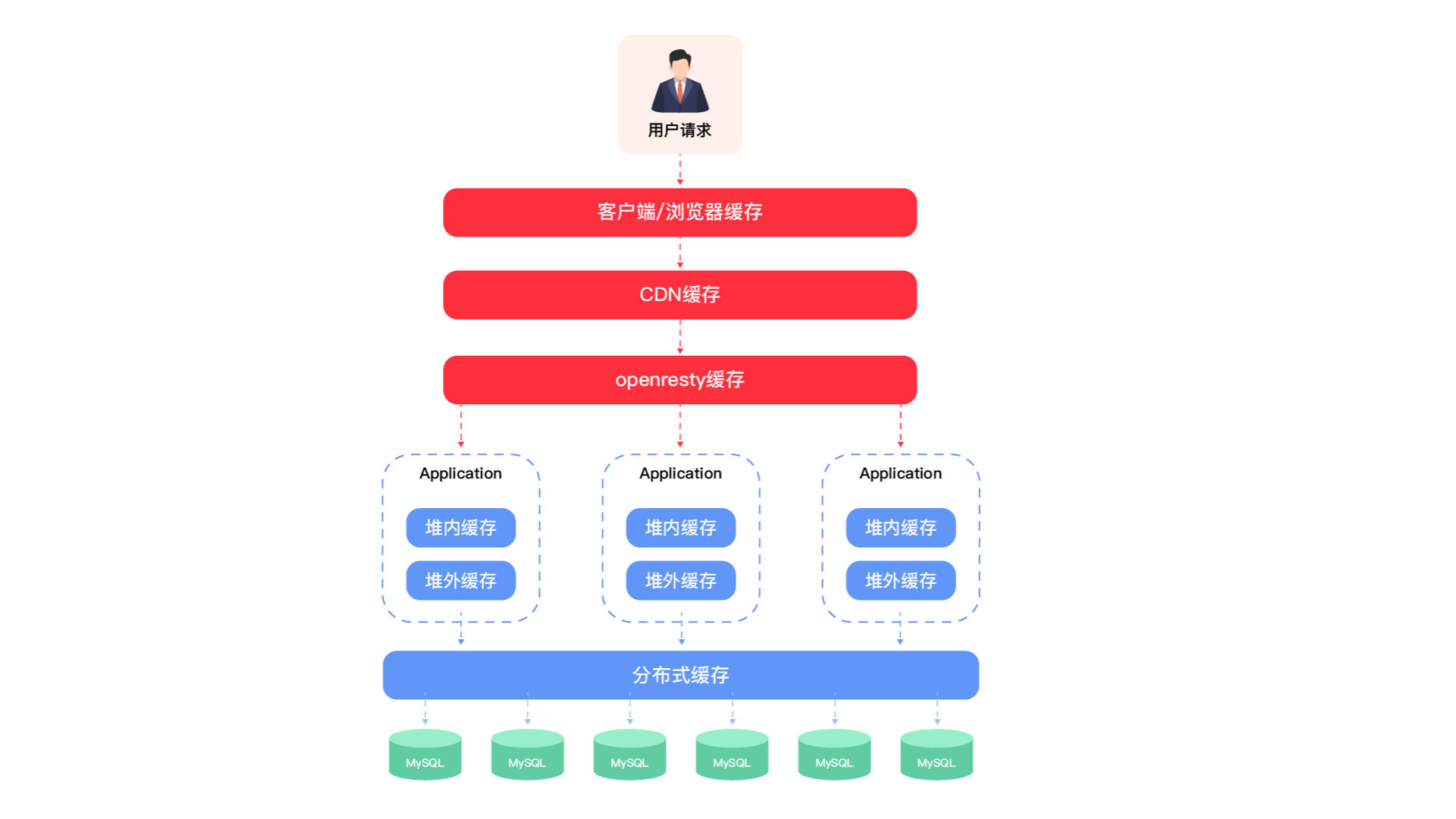
缓存调优
需求分析
需要在页面上显示广告的信息。
表结构分析:
tb_ad (广告表)
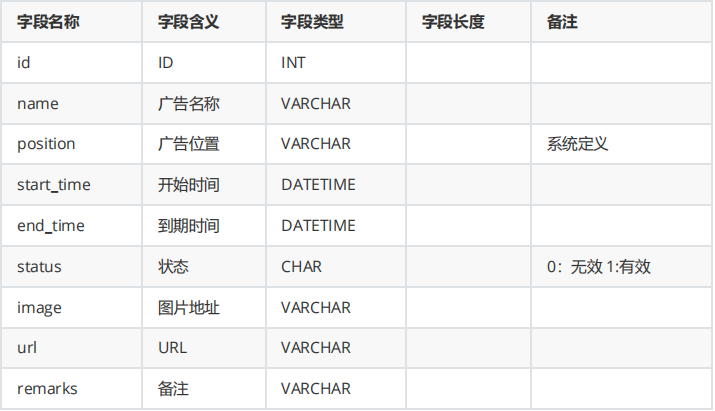
position:系统定义的广告位置
web_index_lb 首页轮播图
web_index_mobile_lb 手机分类轮播图
web_index_book_lb 图书分类轮播图
直接查询数据库
数据库查询:
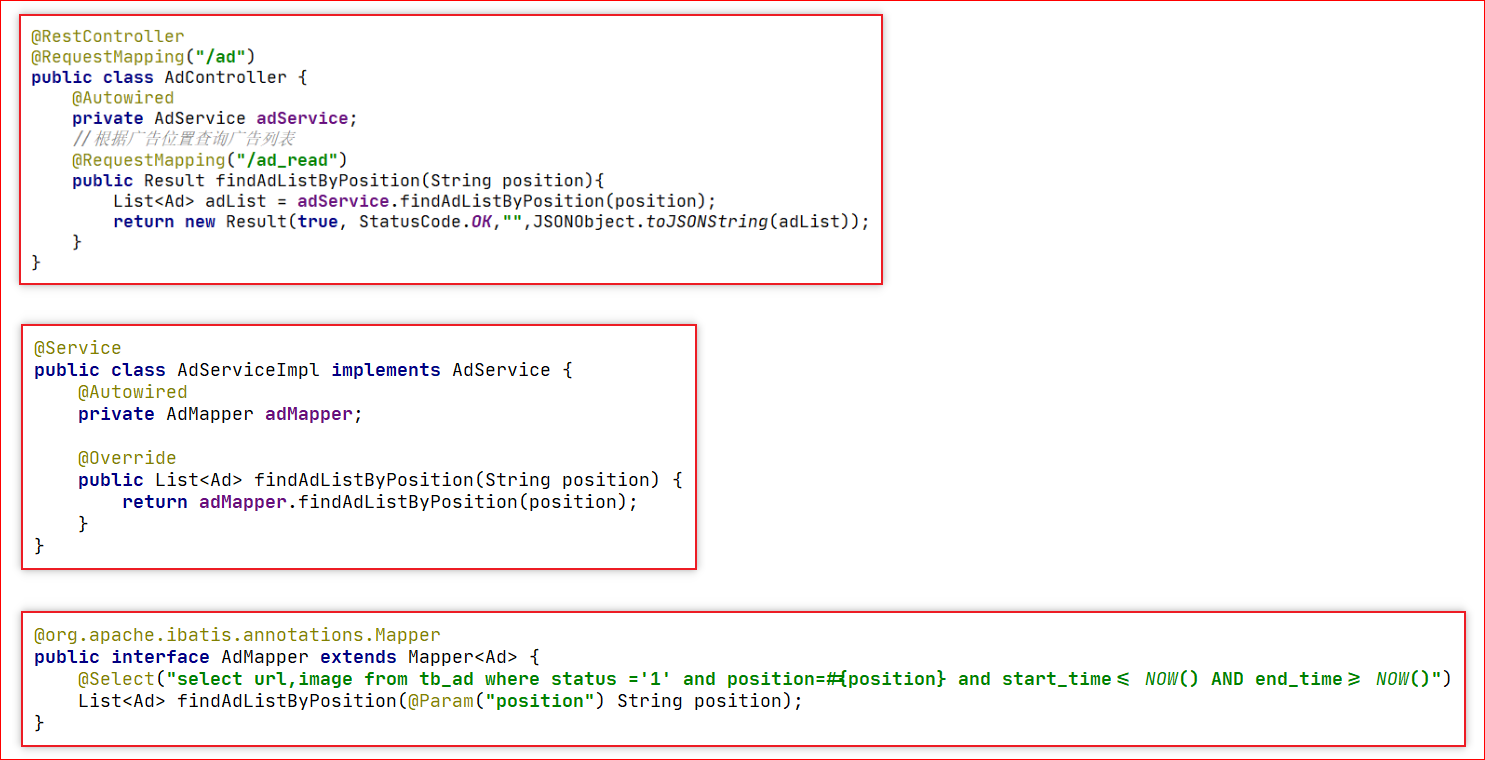
之前接口都是查询数据库,这里本接口压力测试省略
多级缓存
缓存预热与二级缓存 查询思路分析
步骤一:编写Lua脚本实现缓存预热(将mysql里的数据查询出来存入redis)
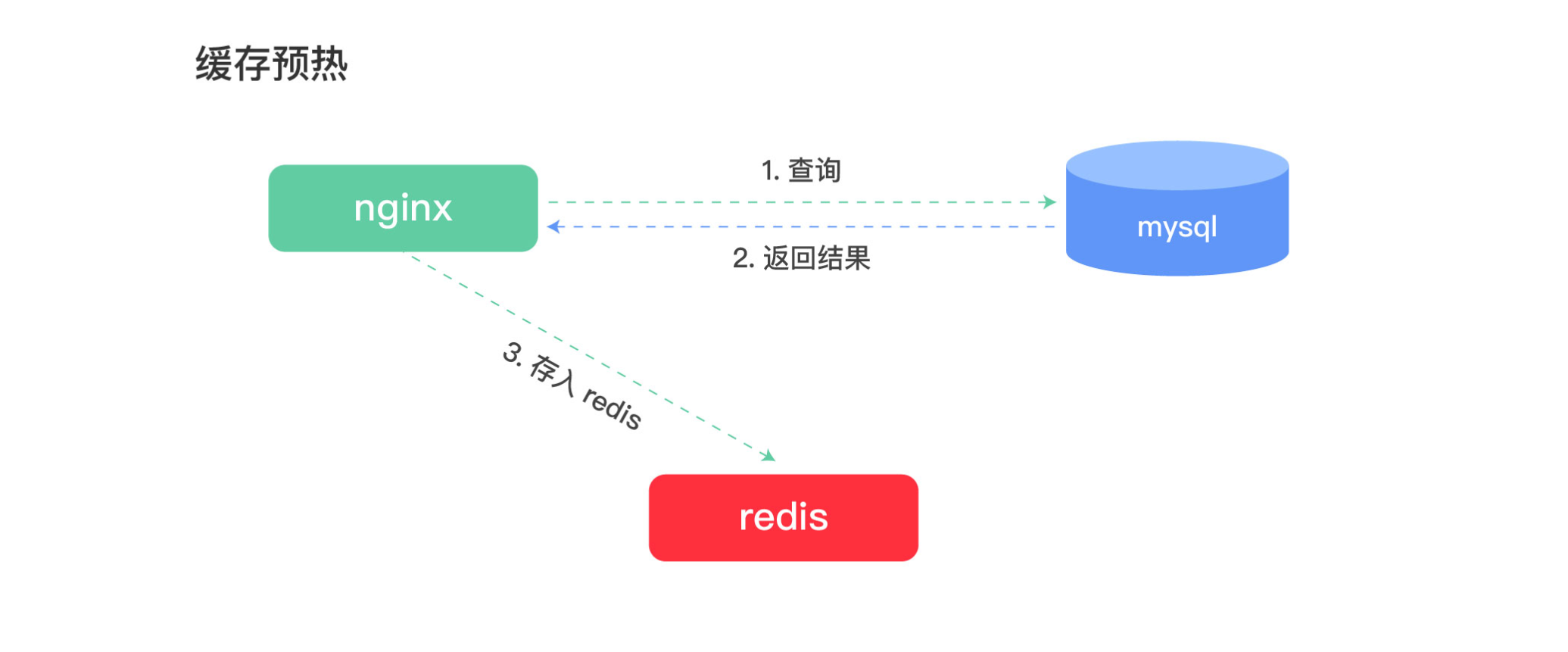
步骤二:编写Lua脚本实现二级缓存读取

缓存预热
实现思路:定义请求:用于查询数据库中的数据更新到redis中。
(1)连接mysql ,按照广告分类ID读取广告列表,转换为json字符串。
(2)连接redis,将广告列表json字符串存入redis 。
定义请求:
请求:
/ad_load
参数:
position --指定广告位置
返回值:
json在/root/lua目录下创建ad_load.lua ,实现连接mysql 查询数据 并存储到redis中
http://hero01/ad/load?position=xxx
-- 设置请求
ngx.header.content_type="application/json;charset=utf8"
-- 引入json第三方依赖
local cjson = require("cjson")
local mysql = require("resty.mysql")
local uri_args = ngx.req.get_uri_args()
local position = uri_args["position"]
local db = mysql:new()
db:set_timeout(1000)
local props = {
host = "172.17.187.78",
port = 3307,
database = "hero_all",
user = "root",
password = "hero@202207"
}
local res = db:connect(props)
local select_sql = "select url,image from tb_ad where status ='1' and
position='"..position.."' and start_time<= NOW() AND end_time>= NOW()"
res = db:query(select_sql)
db:close()
local redis = require("resty.redis")
local red = redis:new()
red:set_timeout(2000)
local ip ="172.17.187.78"
local port = 6379
red:connect(ip,port)
red:set("ad_"..position,cjson.encode(res))
red:close()
ngx.say("{flag:true}")修改/usr/local/hero/openresty/nginx/conf/nginx.conf文件:
代码如下:
#user nobody;
user root root;
# 添加
location /ad_load {
content_by_lua_file /root/lua/ad_load.lua;
}重新加载nginx配置
# 启动nginx
/usr/local/openresty/nginx/sbin/nginx -c
/usr/local/openresty/nginx/conf/nginx.conf
ps -ef | grep nginx
# 停止nginx
/usr/local/openresty/nginx/sbin/nginx -s stop #停止服务
# 重新加载配置,修改配置后执行
/usr/local/openresty/nginx/sbin/nginx -s reload测试:http://hero01/ad_load?position=web_index_lb
广告缓存读取
实现思路:
定义请求,用户根据广告分类的ID 获取广告的列表。通过lua脚本直接从redis中获取数据即可。
定义请求:
请求:/ad_read
参数:position
返回值:json在/root/lua目录下创建ad_read.lua
--设置响应头类型
ngx.header.content_type="application/json;charset=utf8"
--获取请求中的参数ID
local uri_args = ngx.req.get_uri_args();
local position = uri_args["position"];
--引入redis库
local redis = require("resty.redis");
--创建redis对象
local red = redis:new()
--设置超时时间
red:set_timeout(2000)
--连接
local ok, err = red:connect("172.17.187.78", 6379)
--获取key的值
local rescontent=red:get("ad_"..position)
--输出到返回响应中
ngx.say(rescontent)
--关闭连接
red:close()在/usr/local/openresty/nginx/conf/nginx.conf中server下添加配置
location /ad_read {
content_by_lua_file /root/lua/ad_read.lua;
}测试 http://hero01/ad_read?position=web_index_lb 输出
[{"url":"img\/banner1.jpg","image":"img\/banner1.jpg"},
{"url":"img\/banner2.jpg","image":"img\/banner2.jpg"}]测试结果
JMeter:聚合报告、TPS、RT

Nginx-CPU、内存、网络
- 资料:压力测试\08-Nginx-Redis
数据库服务-CPU、内存、网络
- 资料:压力测试\08-Nginx-Redis
小英雄服务-CPU、内存、网络
- 资料:压力测试\08-Nginx-Redis
小结:TPS大幅提升,RT显著降低
进程内缓存
如上的方式没有问题,但是如果请求都到redis,redis压力也很大,所以我们一般采用多级缓存的方式来减少下游系统的服务压力。
配置进程内缓存
先查询openresty本地缓存 如果没有再查询redis中的数据
修改/root/lua目录下ad_read_nginx_cache文件, 内容如下:
--设置响应头类型 ngx.header.content_type="application/json;charset=utf8" --获取请求中的参数ID local uri_args = ngx.req.get_uri_args(); local position = uri_args["position"]; --获取本地缓存 local cache_ngx = ngx.shared.dis_cache; --根据ID 获取本地缓存数据 local adCache = cache_ngx:get('ad_cache_'..position); if adCache == "" or adCache == nil then --引入redis库 local redis = require("resty.redis"); --创建redis对象 local red = redis:new() --设置超时时间 red:set_timeout(2000) --连接 local ok, err = red:connect("172.17.187.78", 6379) --获取key的值 local rescontent=red:get("ad_"..position) --输出到返回响应中 ngx.say(rescontent) --关闭连接 red:close() --将redis中获取到的数据存入nginx本地缓存,缓存有效期10分钟 cache_ngx:set('ad_cache_'..position, rescontent, 1060); else --nginx本地缓存中获取到数据直接输出 ngx.say(adCache) end修改nginx配置文件vi /usr/local/hero/openresty/nginx/conf/nginx.conf ,http节点下添加配置:
#包含redis初始化模块 lua_shared_dict dis_cache 5m; #共享内存开启 location /ad_read_nginx_cache { content_by_lua_file /root/lua/ad_read_nginx_cache.lua; }
http://hero01/ad_read_nginx_cache?position=web_index_lb
测试报告
JMeter:聚合报告、TPS、RT

Nginx-CPU、内存、网络
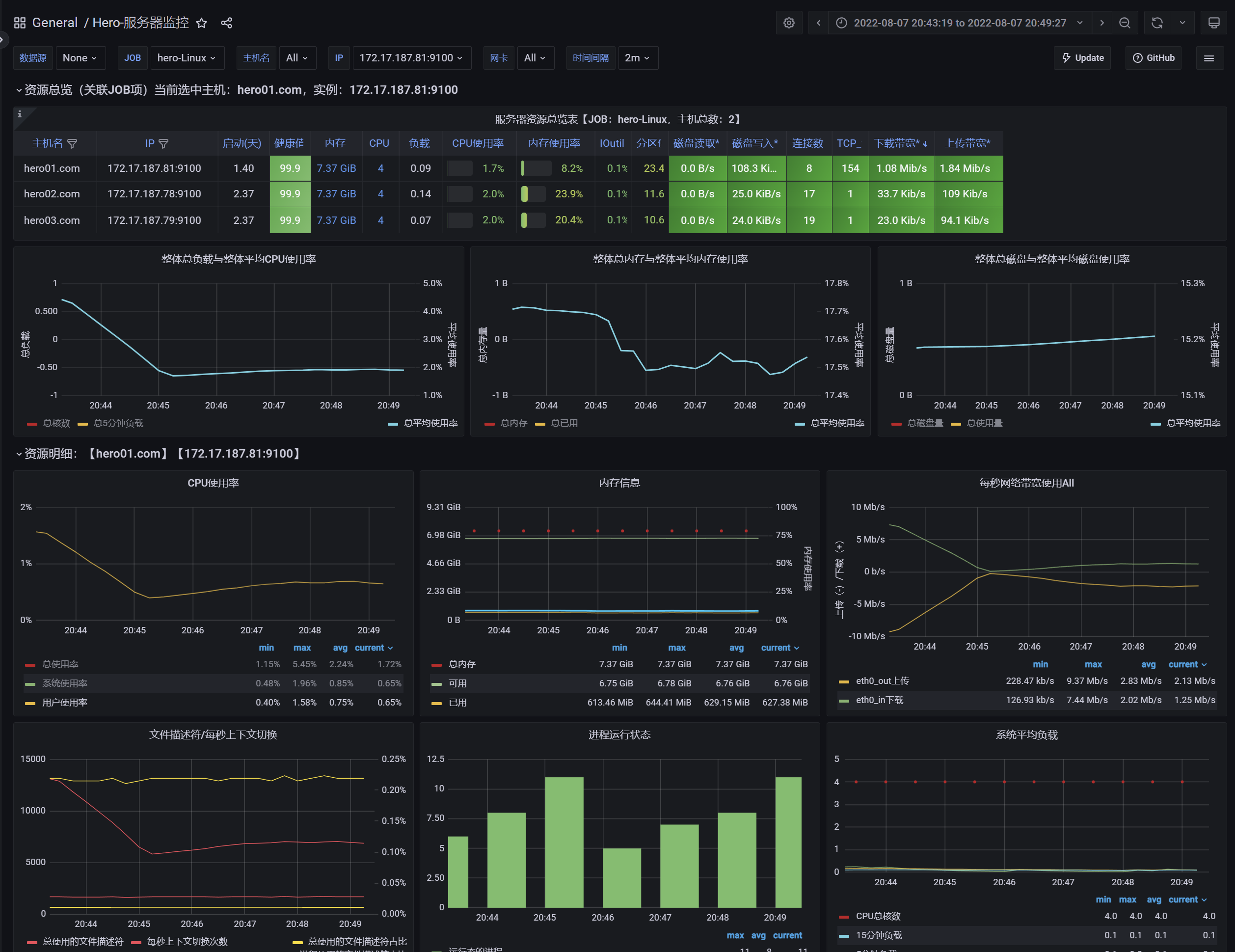
小结:
- TPS继续提升,RT响应时间触底12-20ms之间
- 网络带宽占用大幅下降
JVM调优
那种配置性能更好?当下的两个配置,完全不能反应性能。内存大小合适才好,不是越大越好!给多了反而影响性能!
# 配置01-用大内存,反而会适得其反
JAVA_OPT="-Xms4096M -Xmx4096M -Xmn1024M"
# 配置02-用大内存,反而会适得其反
JAVA_OPT="-Xms512M -Xmx512M -Xmn256M"
# 初始堆大小Xms
# 最大堆大小Xmx
# 年轻代大小Xmn为什么JVM调优?
调优的最终目的都是为了应用程序使用最小的硬件消耗来承载更大的吞吐量。JVM调优主要是针对垃圾收集器的收集性能进行优化,减少GC的频率和Full GC的次数。从而令运行在虚拟机上的应用,能够使用更少的内存,用更低的延迟,获得更大吞吐量,和减少应用的GC暂停时间!GC暂停会在高并发场景下,P99百分位的响应时间会产生影响。
什么时候JVM调优?
遇到以下情况,就需要考虑进行JVM调优:
系统吞吐量与响应性能不高或下降
Heap内存(老年代)持续上涨达到设置的最大内存值
Full GC 次数频繁
GC 停顿时间过长,运行P99百分位响应时间;
应用出现OutOfMemory 等内存异常;
应用中有使用本地缓存,且占用了大量的内存空间;
调优调什么?
JVM调优核心是什么?
内存分配 + 垃圾回收!
合理使用堆内存
GC高效回收垃圾对象,释放内存空间
是否可以把内存空间设置足够大,那么就不需要回收垃圾呢?
问题背景:JVM回收垃圾时机,当JVM内存占满触发垃圾回收!
不可以原因如下:
不回收垃圾,内存增长巨快,再大的空间都不够用;10w请求,3GB垃圾对象
物理层面:64位操作系统可以支持非常大的内存,但不是无限
32位操作系统: 2~32 = 4GB
64位操作系统: 2~64 =16384PB
内存设置既不能太大,也不能太小需要基于业务场景平衡考量:内存空间设置过大,一旦内存空间触发垃圾回收,就会非常危险,寻找这个垃圾非常耗时,由于内存空间足够大,寻找这个垃圾的时候,极其的消耗时间,因此导致程序停顿;
举个栗子:房子足够大,是不是就可以不用打扫卫生?显然是不行的
调优原则及目标:
- 优先原则:优先架构调优和代码调优,JVM优化是不得已的手段
- 大多数的Java应用不需要进行JVM优化
- 观测性原则:发现问题解决问题,没有问题不找问题
调优目标:
下面展示了一些JVM调优的量化目标的参考。注意:不同应用的JVM调优量化目标是不一样的。
- 堆内存使用率 <= 70%;
- 老年代内存使用率<= 70%;
- avg pause <= 1秒;
- Full GC 次数0 或 avg pause interval >= 24小时 ;
- 创建更多的线程
再写一个稍微复杂一点的调优配置:看的出来这两者配置之间的区别吗?
JVM配置01
JAVA_OPT="${JAVA_OPT} -Xms836m -Xmx836m -XX:MetaspaceSize=128m -Xss512k"
JAVA_OPT="${JAVA_OPT} -XX:+UseParallelGC -XX:+UseParallelOldGC "
JAVA_OPT="${JAVA_OPT} -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -
XX:+PrintGCDateStamps -XX:+PrintHeapAtGC -Xloggc:${BASE_DIR}/logs/gc-pspo.log"JVM配置02
JAVA_OPT="${JAVA_OPT} -Xms1024m -Xmx1024m -XX:MetaspaceSize=256m -Xss512k"
JAVA_OPT="${JAVA_OPT} -XX:+UseParNewGC -XX:+UseConcMarkSweepGC "
JAVA_OPT="${JAVA_OPT} -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -
XX:+PrintGCDateStamps -XX:+PrintHeapAtGC -Xloggc:${BASE_DIR}/logs/gc-parnewcms.log"到目前为止,压测和调优做完了。
参考资料
项目性能测试报告模板
项目性能测试报告模板压测脚本
链接: https://pan.baidu.com/s/19O-tTSyWzkL_Oj6RNxUU4A?pwd=cjqf 提取码: cjqf
