JVM调优实践
为什么JVM调优?
运行在虚拟机上的应用,能够使用更少的内存(Footprint),及更低的延迟(Latency),获取更大的吞吐量(Throughput)。
下面展示了一些JVM调优的量化目标参考实例
调优目标:
- 堆内存使用率 <= 70%;
- 老年代内存使用率<= 70%;
- avg pause <= 1秒;
- Full GC 次数0 或 avg pause interval >= 24小时 ;
注意:不同应用场景的JVM调优量化目标是不一样的,这里的目标只一个参照模板。
什么时候JVM调优?
遇到以下情况,就需要考虑进行JVM调优:
系统吞吐量下降与响应延迟(P99);
Heap内存(老年代)持续上涨至出现OOM;
Full GC 次数频繁;
GC 停顿过长(超过1秒);
应用出现OutOfMemory 等内存异常;
应用中有使用本地缓存且占用大量内存空间;
调优调什么?
内存分配 + 垃圾回收!
合理使用堆内存
GC高效回收占用的内存的垃圾对象
GC高效释放掉内存空间
调优原则
- 优先原则:优先架构调优和代码调优,JVM优化是不得已的手段
- 大多数的Java应用不需要进行JVM优化
- 观测性原则:发现问题解决问题,没有问题不找问题
JVM实践调优主要步骤
第一步:监控分析GC日志
第二步:判断JVM问题:
- 如果各项参数设置合理,系统没有超时日志出现,GC频率不高,GC耗时不高,那么没有必要进行GC优化
- 如果GC时间超过1秒,或者频繁GC,则必须优化。
第三步:确定调优目标
第四步:调整参数
- 调优一般是从满足程序的内存使用需求开始,之后是时间延迟需求,最后才是吞吐量要求,要基于这个步骤来不断优化,每
一个步骤都是进行下一步的基础,不可逆行之。
第五步:对比调优前后差距
第六步:重复:1、2、3、4、5步骤
- 找到最佳JVM参数设置
第七步:应用JVM参数到应用服务器:
- 找到最合适的参数,将这些参数灰度发布一部分机器,观察一段时间。
- 如果,观察结果可以验证方案的价值,则进行全量发布!
GC日志详解
参数配置
JVM调优典型参数设置:
- -Xms堆内存最小值
- -Xmx堆内存最大值
- -Xmn新生代内存的最大值
- -Xss每个线程的栈内存
# 计算最大线程数的公式:理论上限
Number of threads = (MaxProcess内存 - JVM内存 - ReservedOsMemory) /(ThreadStackSize)
系统最大可创建的线程数量=(机器本身可用内存 - (JVM分配的堆内存+JVM元数据区)) / Xss的值建议:在开发测试环境可以用Xms和Xmx设置最小值最大值,但是在线上生产环境,Xms和Xmx设置的值相同防止抖动;
JVM调优设置合大小堆内存空间,既不能太大,也不能太小。那么应该设置为多少呢?
JAVA_OPT=”-Xms4096m -Xmx4096m -Xmn1024m”
JAVA_OPT=”-Xms512m -Xmx512m -Xmn256m
默认的配置是否存在性能瓶颈!
如果想要确定JVM性能问题瓶颈,需要分析GC日志
-XX:+PrintGCDetails 开启GC日志创建更详细的GC日志,默认关闭
-XX:+PrintGCTimeStamps,-XX:+PrintGCDateStamps 开启GC时间提示,
- 开启时间便于我们更精确地判断几次GC操作之间的时两个参数的区别
- 时间戳是相对于0(依据JVM启动的时间)的值,而日期戳(date stamp)是实际的日期字符串
- 由于日期戳需要进行格式化,所以它的效率可能会受轻微的影响,不过这种操作并不频繁,它造成的影响也很难被我们感知。
-XX:+PrintHeapAtGC 打印堆的GC日志
-Xloggc:./logs/gc.log 指定GC日志路径
# 配置GC日志输出
JAVA_OPT=”${JAVA_OPT} -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps - XX:+PrintHeapAtGC -Xloggc:${BASE_DIR}/logs/gc-default.log “
GC日志解读
Young GC 日志含义
2021-05-18T14:31:11.340+0800: 2.340: [GC (Allocation Failure) [PSYoungGen: 896512K->41519K(1045504K)]896512K-41543K(3435008K), 0.0931965 secs] [Times: user=0.14 sys=0.02, real=0.10 secs]# 第一部分
2021-05-18T14:31:11.340+0800: 2.340: [GC (Allocation Failure)
GC事件开始时间,+0800代表中国所在的东区:2021-05-18T14:31:11.340+0800
GC事件开始时间相对于JVM开始启动的间隔秒数:2.340
区分YoungGC还是FullGC的标志,GC代表YoungGC
触发GC的原因: (Allocation Failure)
# 第二部分
[PSYoungGen: 896512K->41519K(1045504K)] 896512K-41543K(3435008K), 0.0931965 secs]
垃圾收集器的名称:PSYoungGen
在垃圾收集之前 和 之后新时代的使用量:896512K->41519K
新生代总空间大小:(1045504K)
在垃圾收集之前和之后整个堆内存使用量:896512K-41543K
堆总空间大小:(3435008K)
GC持续时间:0.0931965 secs
# 第三部分
[Times: user=0.14 sys=0.02, real=0.10 secs]
GC线程消耗的CPU时间:user=0.14
GC过程中操作系统调用和系统等待事件所消耗的时间:sys=0.02
应用程序暂停的时间:0.10 secsFullGC 日志含义
2021-05-19T14:46:07.367+0800: 1.562: [Full GC (Metadata GC Threshold)[PSYoungGen: 18640K-
>0K(1835008K)] [ParOldGen: 16K->18327K(1538048K)] 18656K->18327K(3373056K), [Metaspace: 20401K-
>20398K(1069056K)], 0.0624559 secs] [Times: user=0.19 sys=0.00, real=0.06 secs]# 第一部分
2021-05-19T14:46:07.367+0800: 1.562: [Full GC (Metadata GC Threshold)
GC事件开始时间,+0800代表中国所在的东区:
GC事件开始时间相对于JVM开始启动的间隔秒数:2.340
区分YoungGC还是FullGC的标志
触发GC的原因: (Allocation Failure)
# 第二部分
[PSYoungGen: 18640K->0K(1835008K)] [ParOldGen: 16K->18327K(1538048K)] 18656K->18327K(3373056K),
垃圾收集器的名称:PSYoungGen
在垃圾收集之前 和 之后新时代的使用量:18640K->0K
新生代总空间大小:(1835008K)
老年代垃圾收集器名称:ParOldGen
在垃圾收集之前和之后老年代的使用量:16K->18327K
老年代总空间大小:(1538048K)
在垃圾收集之前和之后整个堆内存使用量:18656K->18327K
堆总空间大小:(3373056K)
# 第三部分
[Metaspace: 20401K->20398K(1069056K)], 0.0624559 secs] [Times: user=0.19 sys=0.00, real=0.06 secs]
元空间区域垃圾收集器:Metaspace
在垃圾收集之前和之后元空间的使用量:20401K->20398K
元空间大小:(1069056K)
GC事件持续的时间:0.0624559 secs
GC线程消耗的CPU时间:user=0.19
GC过程中,操作系统调用和系统等待事件所消耗的时间:sys=0.00
应用程序暂停时间:real=0.06 secs日志这么看是不是很累?接下来,我们学一个GC日志可视化工具
GC日志可视化分析
分析GC日志,就必须让GC日志输出到一个文件中,然后使用GC日志分析工具(https://gceasy.io/)进行分析。
默认配置
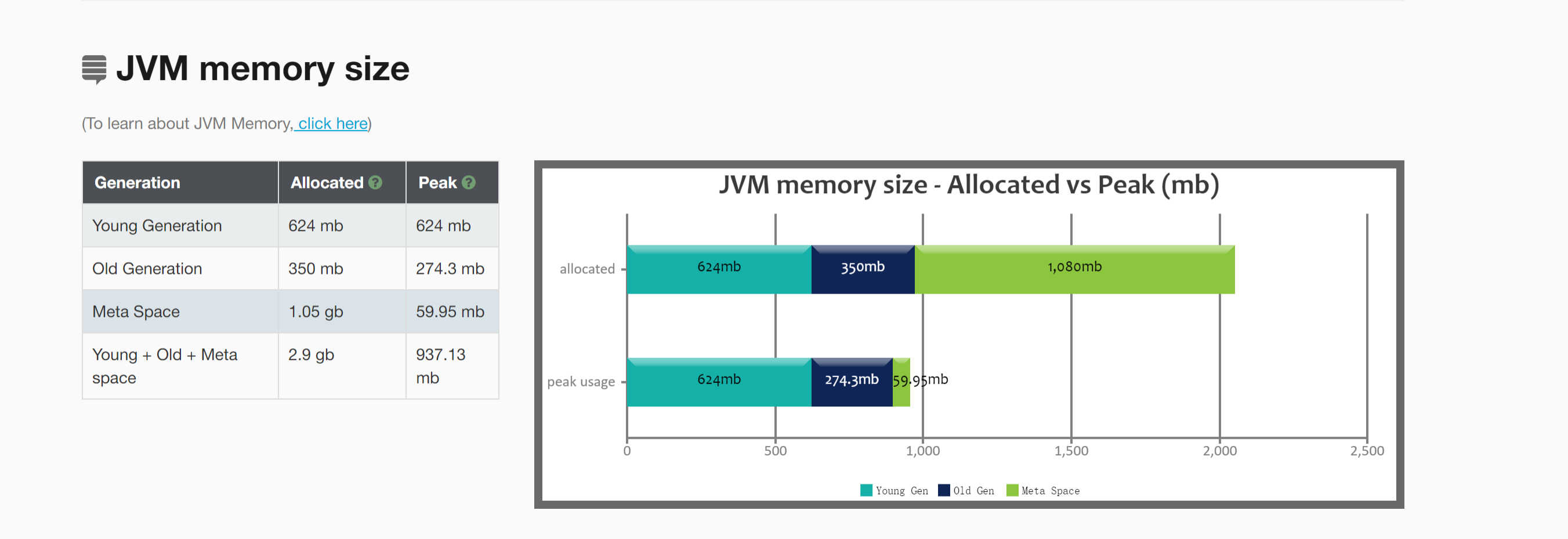
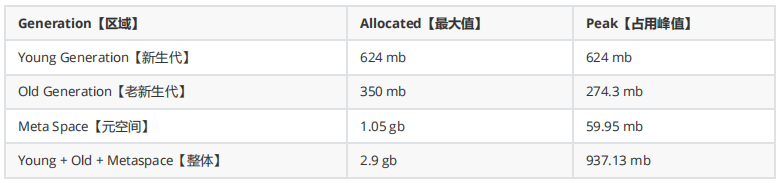
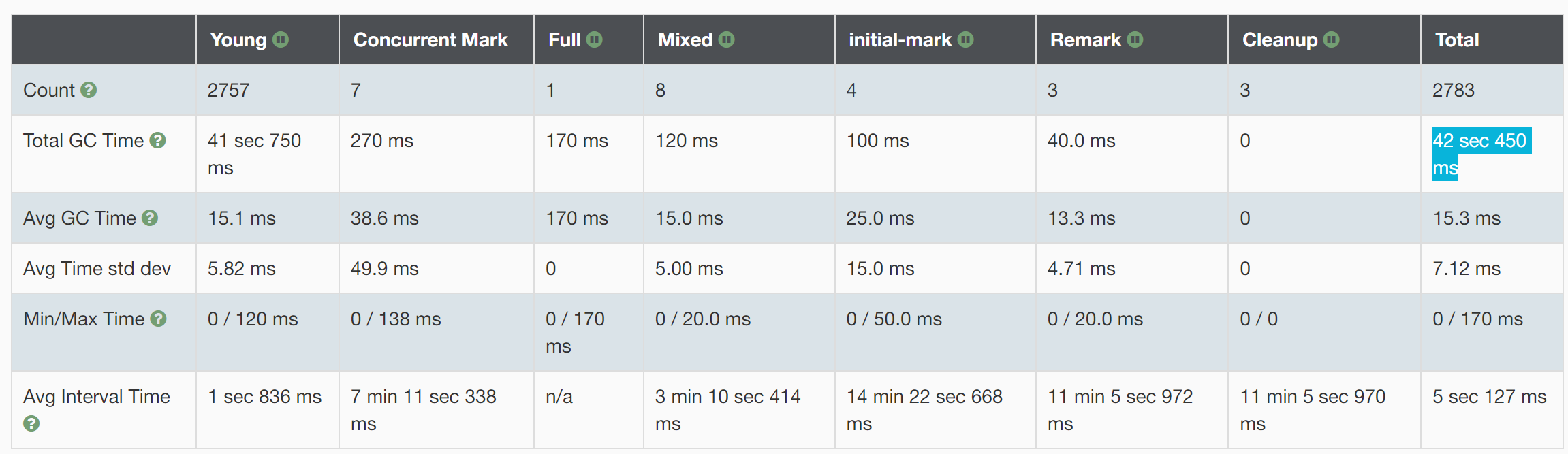
1) JVM内存占用情况:
2) 关键性能指标:
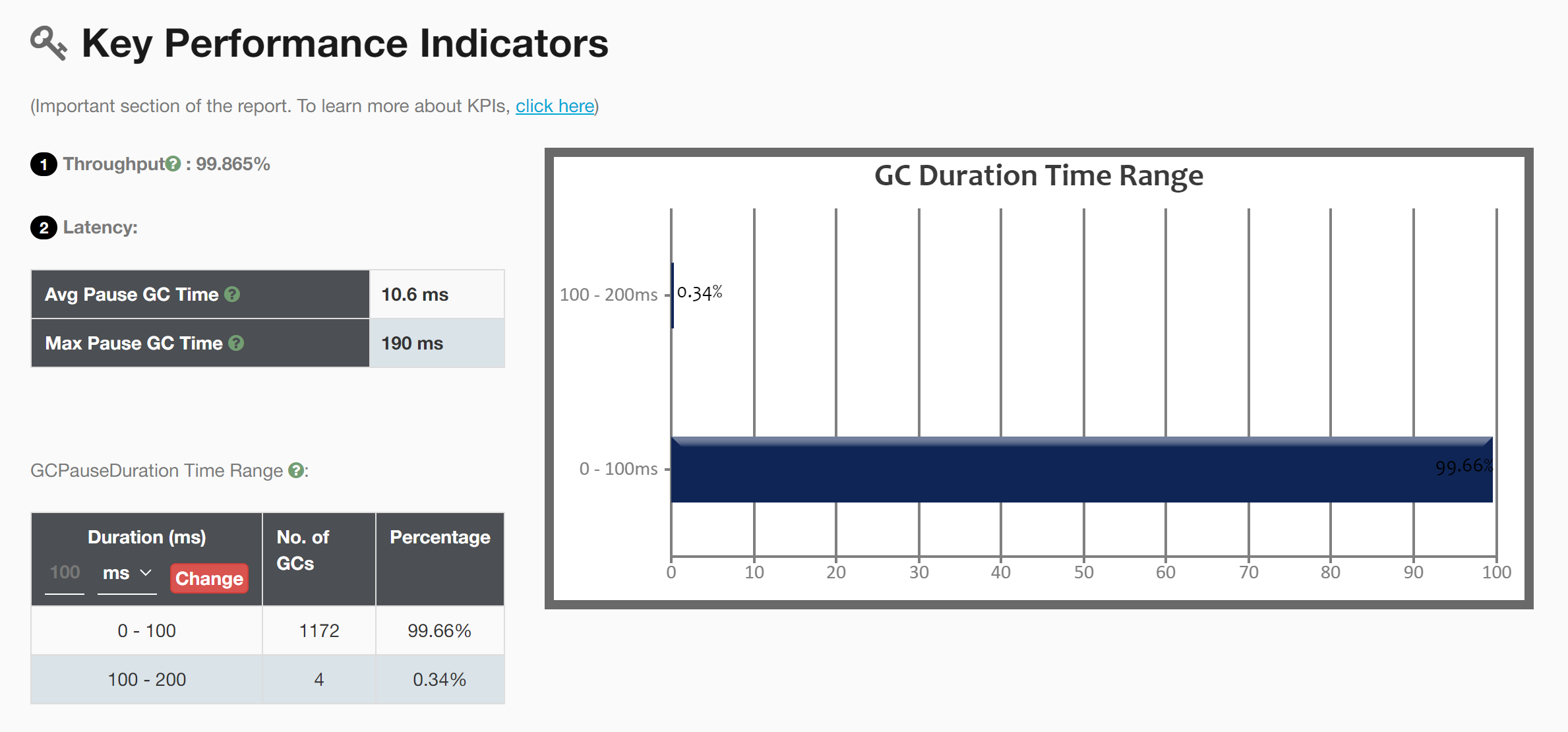
1、吞吐量:百分比越高表明GC开销越低。这个指标反映了JVM的吞吐量。
Percentage of time spent in processing real transactions vs time spent in GC activity. Higher percentage is a good indication that GC overhead is low. One should aim for high throughput.
2、GC 延迟:
- Avg Pause GC Time:10.6ms 平均GC暂停时间
- Max Pause GC Time:190ms最大GC暂停时间
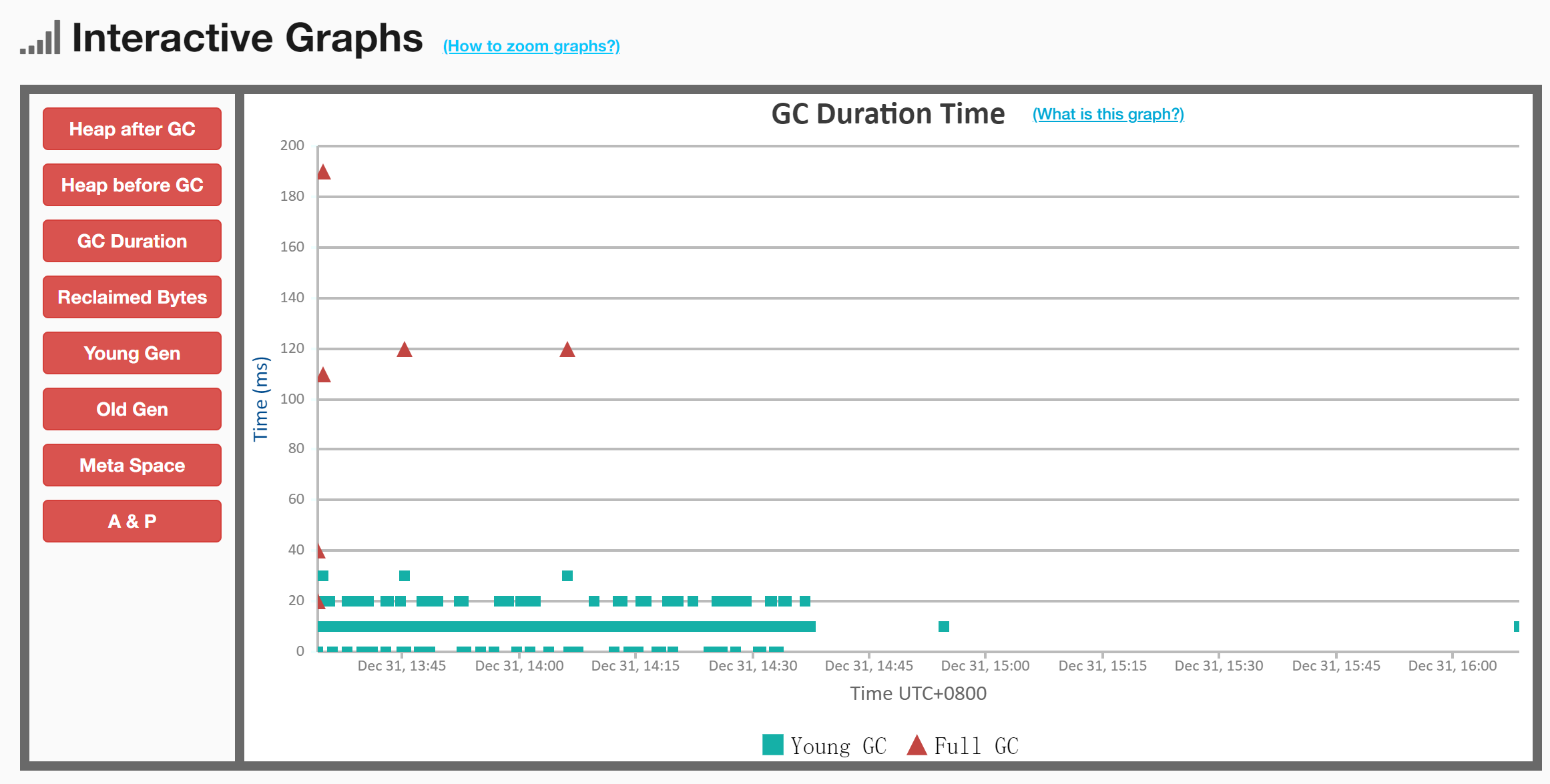
3) GC 可视化交互聚合结果
存在问题:一开始就发生了3次Full GC很明显不正常;
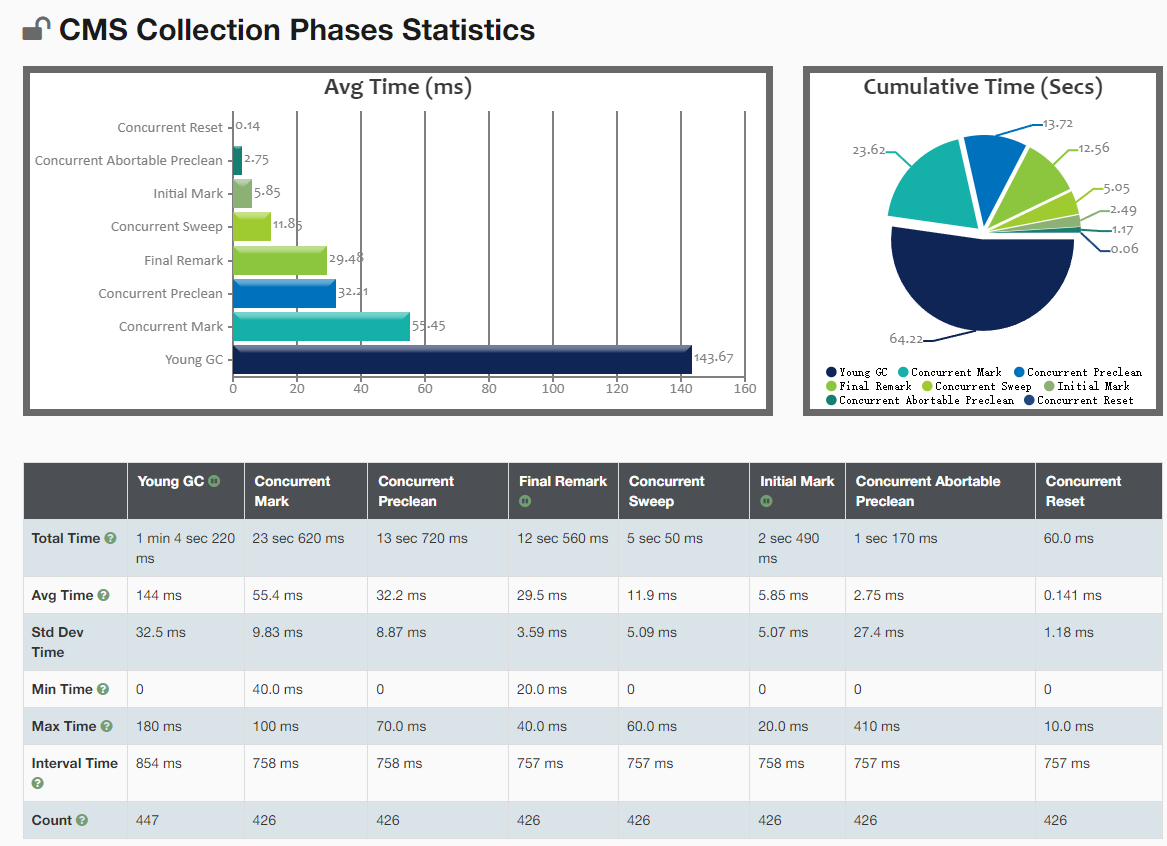
4) GC 统计

5) GC原因:
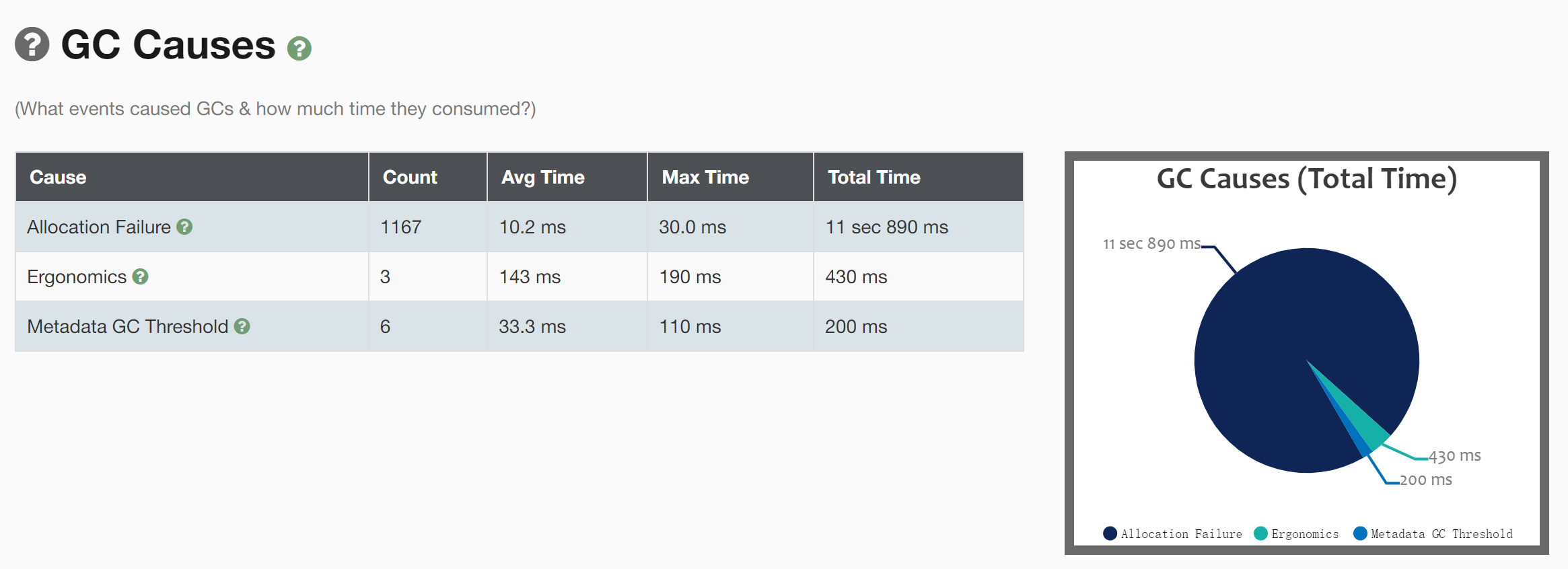

Allocation Failure :新生代空间不足
Metadata GC Threshold: 元空间超阈值
Ergonomics:译文是“人体工程学”,有自适应的意思,GC中的Ergonomics含义是负责自动调解GC暂停时间和吞吐量之间平衡从而产生的GC。目的:使得虚拟机性能更好的一种机制。
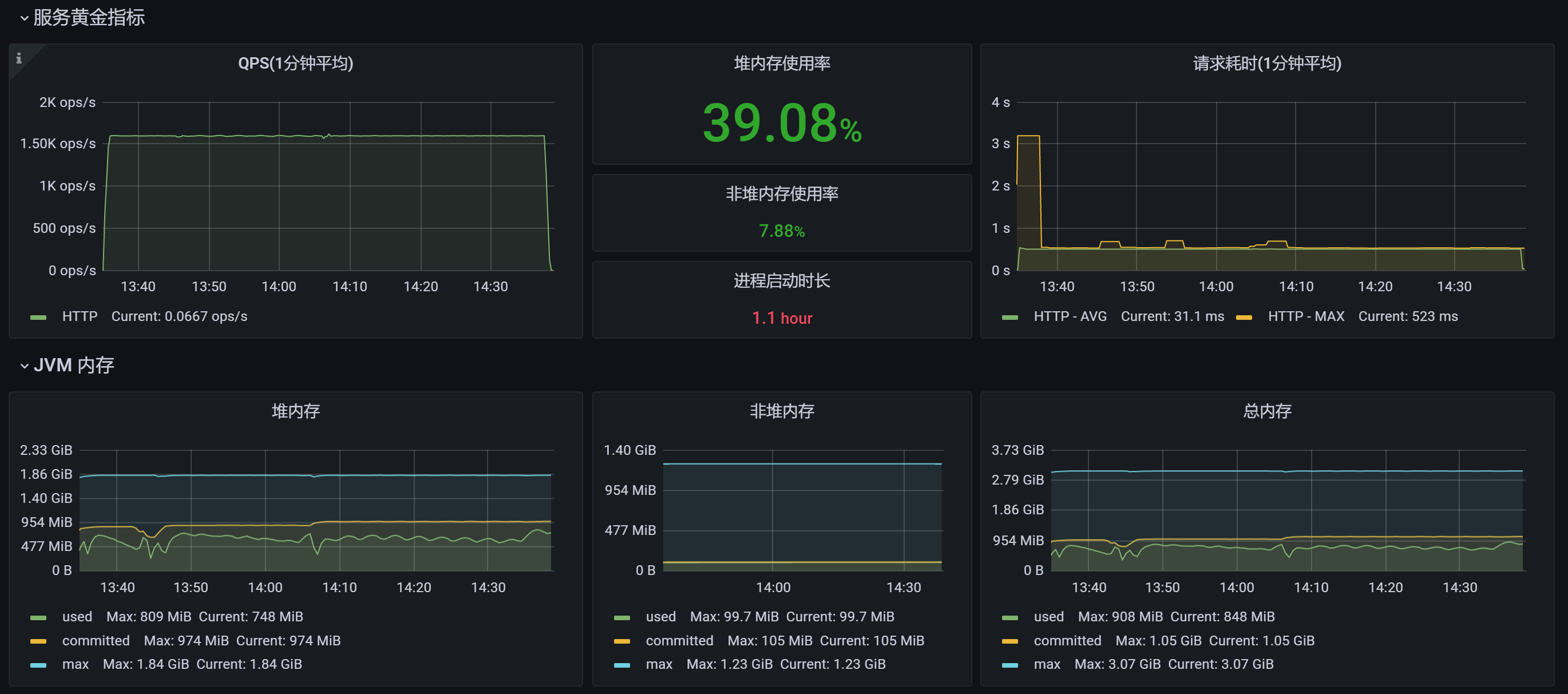
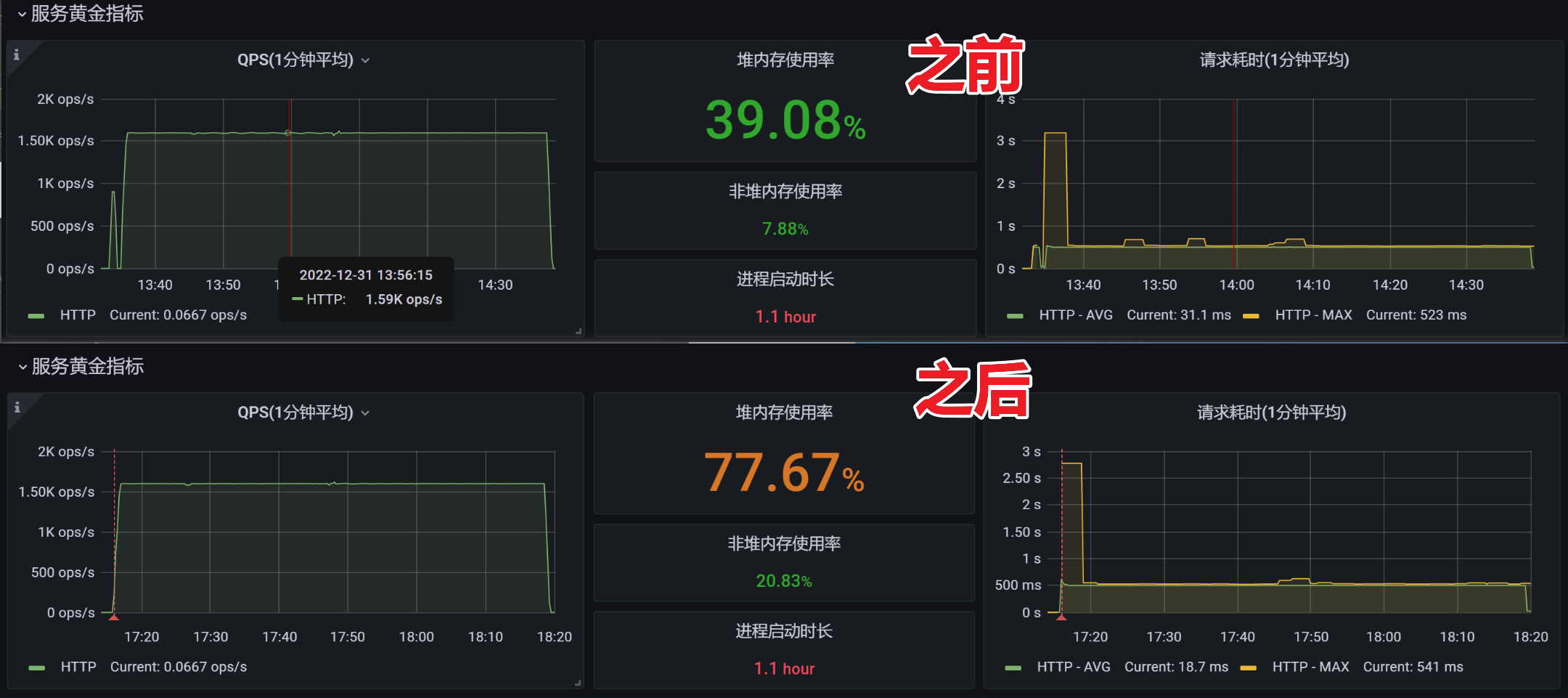
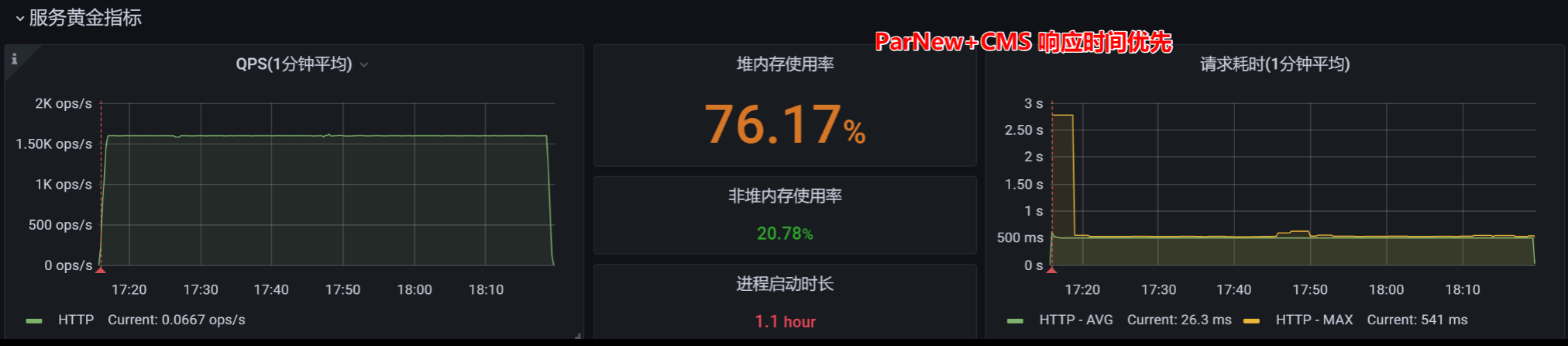
TPS&RT&内存占用:
堆内存与元空间优化
- 堆内存给多少合适?
- 年轻代给多少合适?
- 老年代给多少合适?
- 元空间给多少合适?依据观察的结果,元空间给128,尽量是8的整数倍
- 堆栈给多少合适?
监控分析
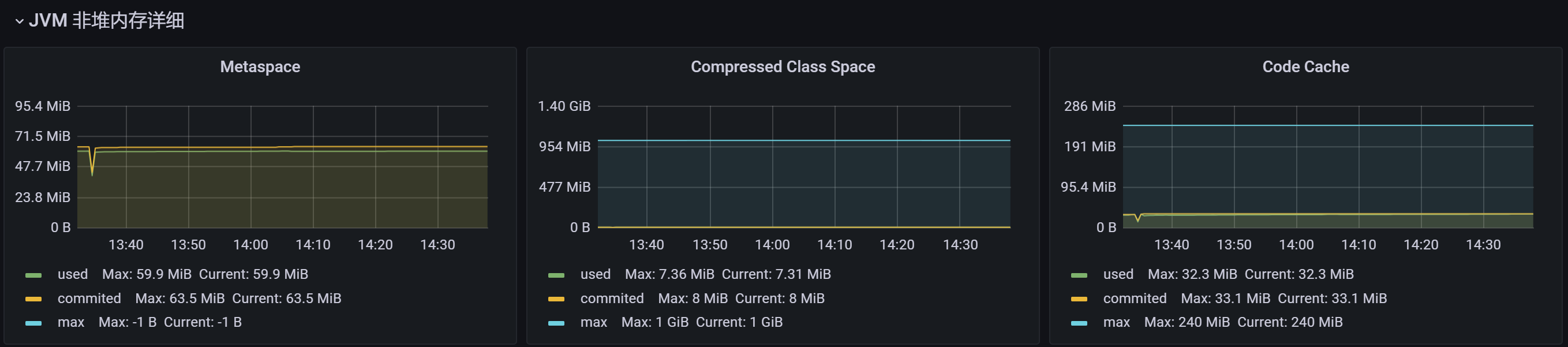
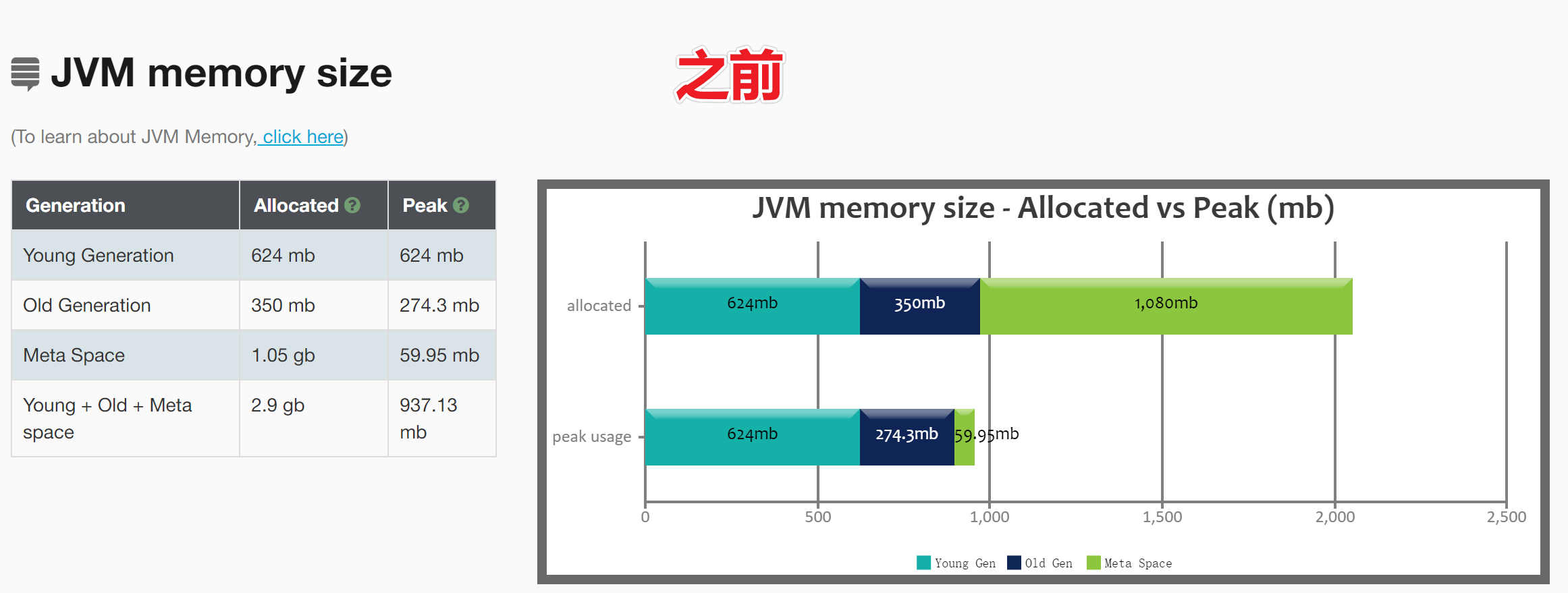
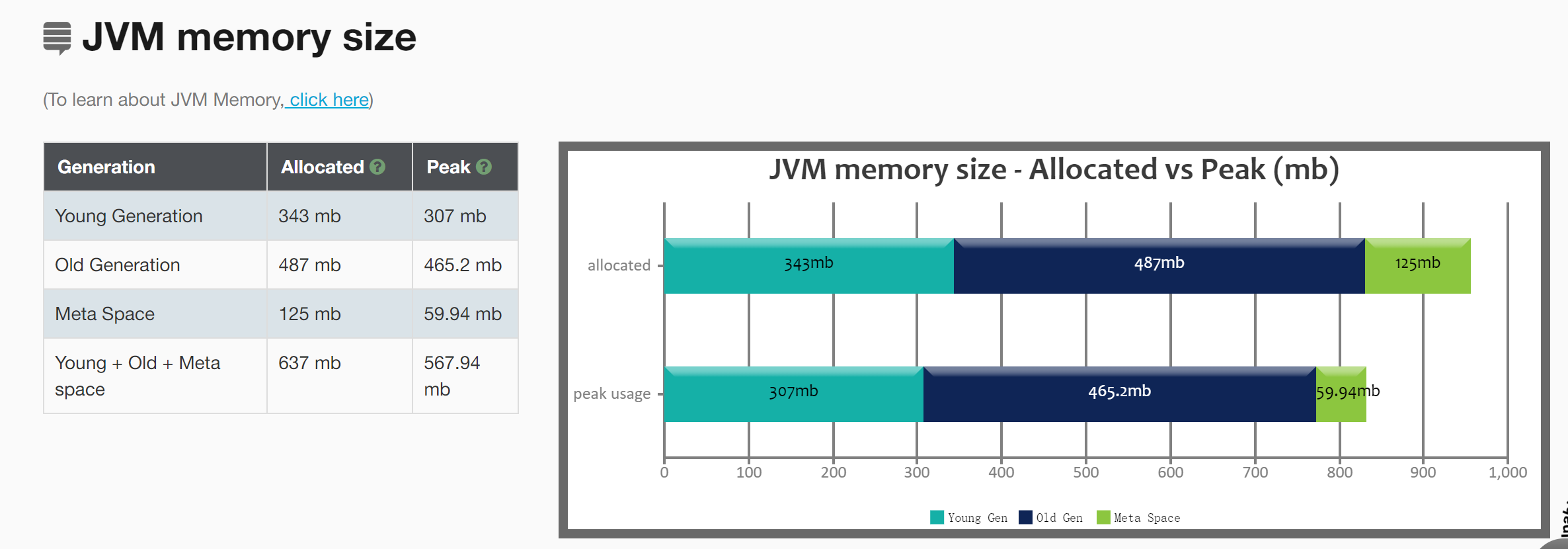
JVM内存占用情况:
- Meta Space空间分配不合理
Young和Full GC趋势:
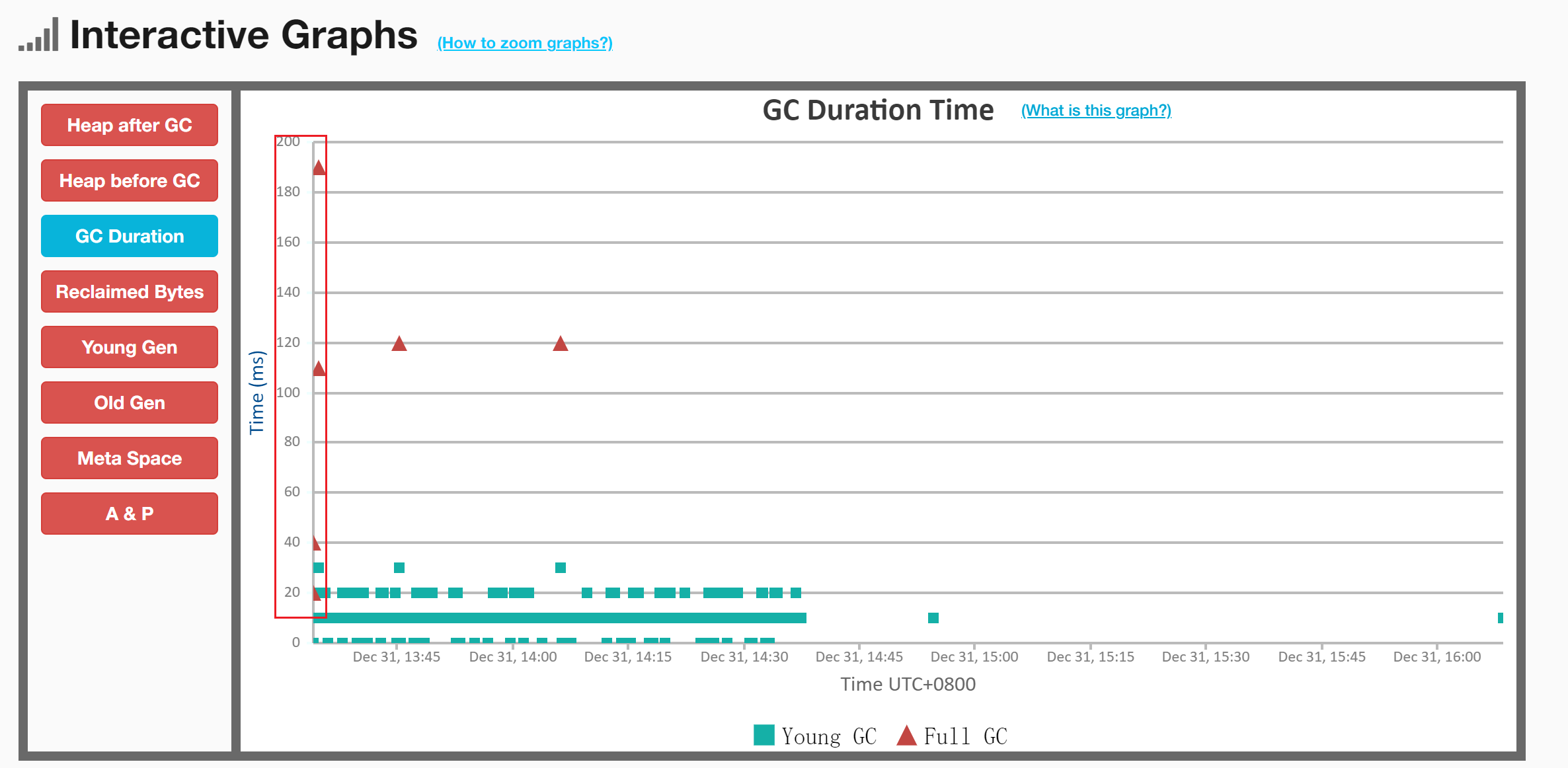
判断
GC主要原因
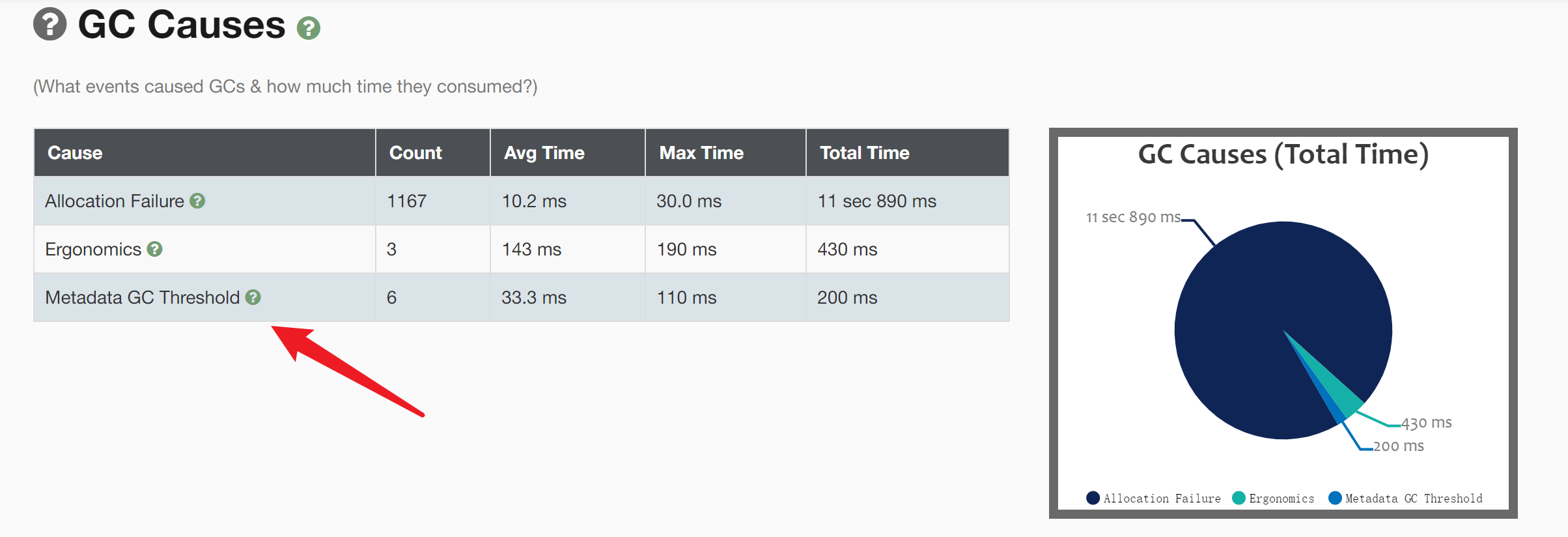
确定目标
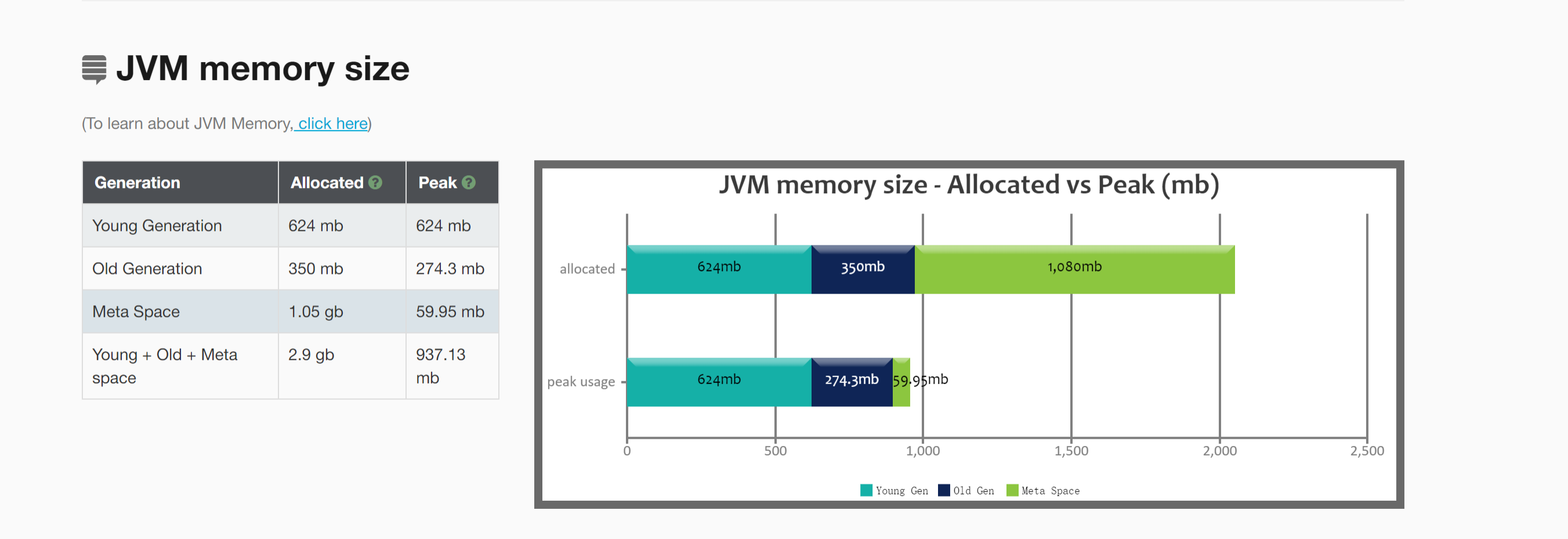
则其他堆空间的分配,基于以下规则来进行。
老年代的空间大小为 274MB【那些不容易消亡的老对象】
- java heap:参数-Xms和-Xmx,建议扩大至3-4倍FullGC后的老年代空间占用。274 (3-4) = (822-1096)MB ,设置heap大小为1096MB,最好是8的整数倍;
- 元空间:参数-XX:MetaspaceSize=N,设置元空间大小为128MB;
- 新生代:参数-Xmn,建议扩大至1-1.5倍FullGC之后的老年代空间占用。274M(1-1.5)=(274 -411)M,设置新生代大小为411MB,最好是8的整数倍,因此改为408M;
# 调整参数,基于当前系统运行情况这是最佳配置
JAVA_OPT="${JAVA_OPT} -Xms1096m -Xmx1096m -Xmn408m -XX:MetaspaceSize=128m -XX:MaxMetaspaceSize=128m"
JAVA_OPT="${JAVA_OPT} -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps -
XX:+PrintHeapAtGC -Xloggc:${BASE_DIR}/logs/gc-best-heap-metaspace.log"对比差异
对比内存占用

对比TPS和RT
线程堆栈优化
对于不同版本的Java虚拟机和不同的操作系统,栈容量最小值可能会有所限制,这主要取决于操作系统内存分页大小。譬如上述方法中的参数-Xss128k可以正常用于32位Windows系统下的JDK 6,但是如果用于64位Windows系统下的JDK 11,则会提示栈容量最小不能低于180K,而在Linux下这个值则可能是228K,如果低于这个最小限制,HotSpot虚拟器启动时会给出如下提示:
The Java thread stack size specified is too small. Specify at least 228k那么问题来了,Xss应该设置多少呢?
JDK5.0以后每个线程堆栈大小为1M,以前每个线程堆栈大小为256。根据应用的线程所需内存大小进行调整。在相同物理内存下,减小这个值能生成更多的线程。但是操作系统对一个进程内的线程数还是有限制的,不能无限生成, 如果栈不是很深, 应该是256k够用了,大的应用建议使用512k。
注意:这个选项对性能影响较大,需严格测试确定最终大小。
# 计算最大线程数的公式:
Number of threads = (MaxProcess内存 - JVM内存 - ReservedOsMemory) / (ThreadStackSize)
系统最大可创建的线程数量 = (机器本身可用内存 - (JVM分配的堆内存+JVM元数据区)) / Xss的值优化后的参数配置:
JAVA_OPT="${JAVA_OPT} -Xms1096m -Xmx1096m -XX:MetaspaceSize=128m -XX:MaxMetaspaceSize=128m -Xss512k"
JAVA_OPT="${JAVA_OPT} -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps -
XX:+PrintHeapAtGC -Xloggc:${BASE_DIR}/logs/gc-best-stack.log"前提:高延迟场景!
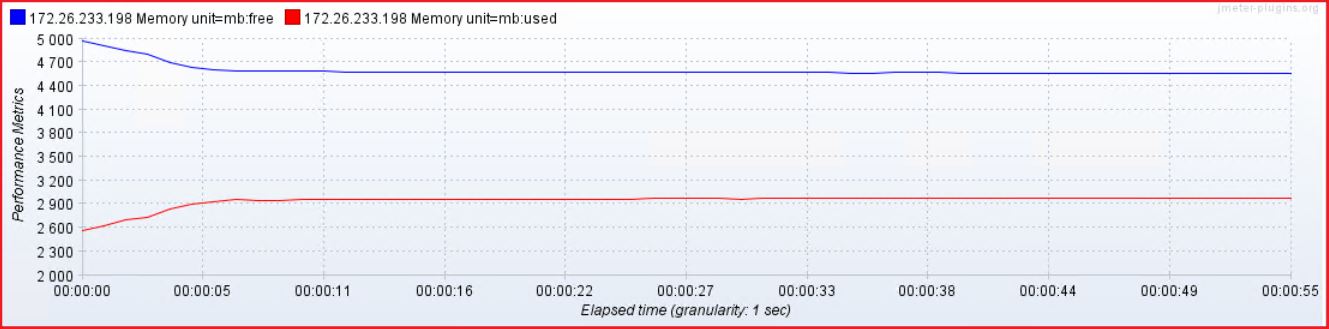
Xss512k内存占用:
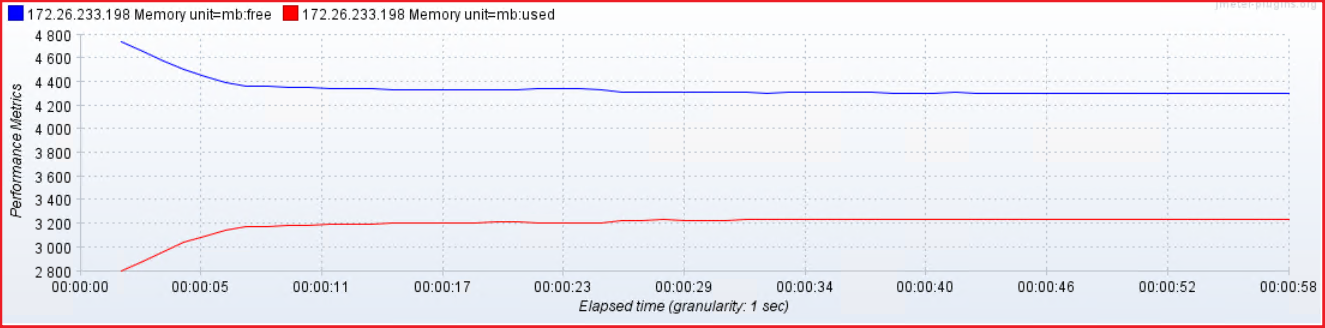
Xss2m内存占用:
垃圾回收器优化:吞吐量优先ps+po
压力提升至1000-3000
默认使用ps+po 垃圾回收器组合: 并行垃圾回收器组合
JAVA_OPT="${JAVA_OPT} -Xms256m -Xmx256m -XX:MetaspaceSize=128m -XX:MaxMetaspaceSize=128m -Xss512k"
JAVA_OPT="${JAVA_OPT} -XX:+UseParallelGC -XX:+UseParallelOldGC "
JAVA_OPT="${JAVA_OPT} -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps -XX:+PrintHeapAtGC -Xloggc:${BASE_DIR}/logs/gc-ps-po.log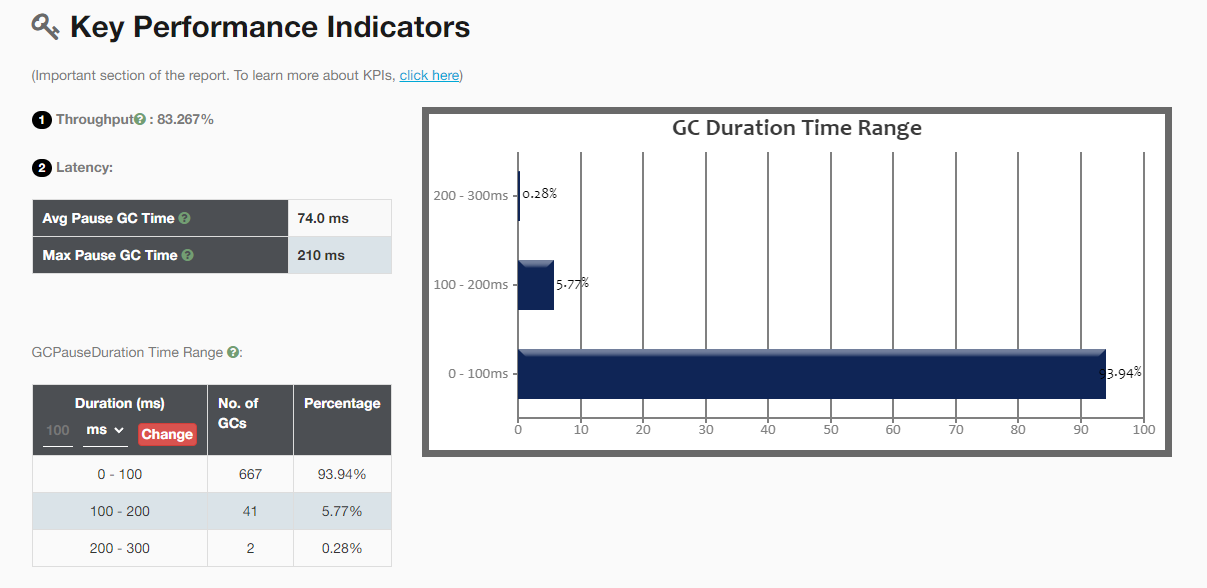
垃圾回收器优化:响应时间优先parnew+cms
压力提升至1000-3000
使用cms垃圾回收器,垃圾回收器组合: parNew+CMS, cms垃圾回收器在垃圾标记,垃圾清除的时候,和业务线程交叉执行,尽量减少stw时间,因此这垃圾回收器叫做响应时间优先;
JAVA_OPT="${JAVA_OPT} -Xms256m -Xmx256m -XX:MetaspaceSize=128m -XX:MaxMetaspaceSize=128m -Xss512k"
JAVA_OPT="${JAVA_OPT} -XX:+UseParNewGC -XX:+UseConcMarkSweepGC "
JAVA_OPT="${JAVA_OPT} -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps -
XX:+PrintHeapAtGC -Xloggc:${BASE_DIR}/logs/gc-parnew-cms.log"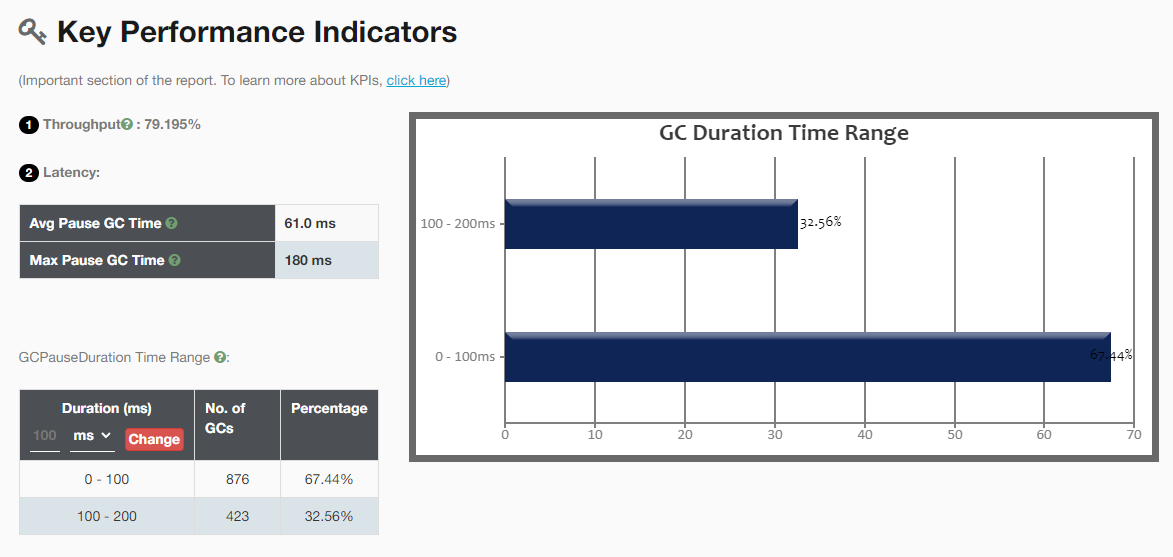
垃圾回收器优化:G1全功能但不全能
配置G1只需要简单三步即可:
第一步,开启G1垃圾收集器
第二步,设置堆的最大内存
第三步,设置最大的停顿时间
JAVA_OPT="${JAVA_OPT} -Xms256m -Xmx256m -XX:MetaspaceSize=128m -XX:MaxMetaspaceSize=128m -Xss512k"
JAVA_OPT="${JAVA_OPT} -XX:+UseG1GC -XX:MaxGCPauseMillis=100"
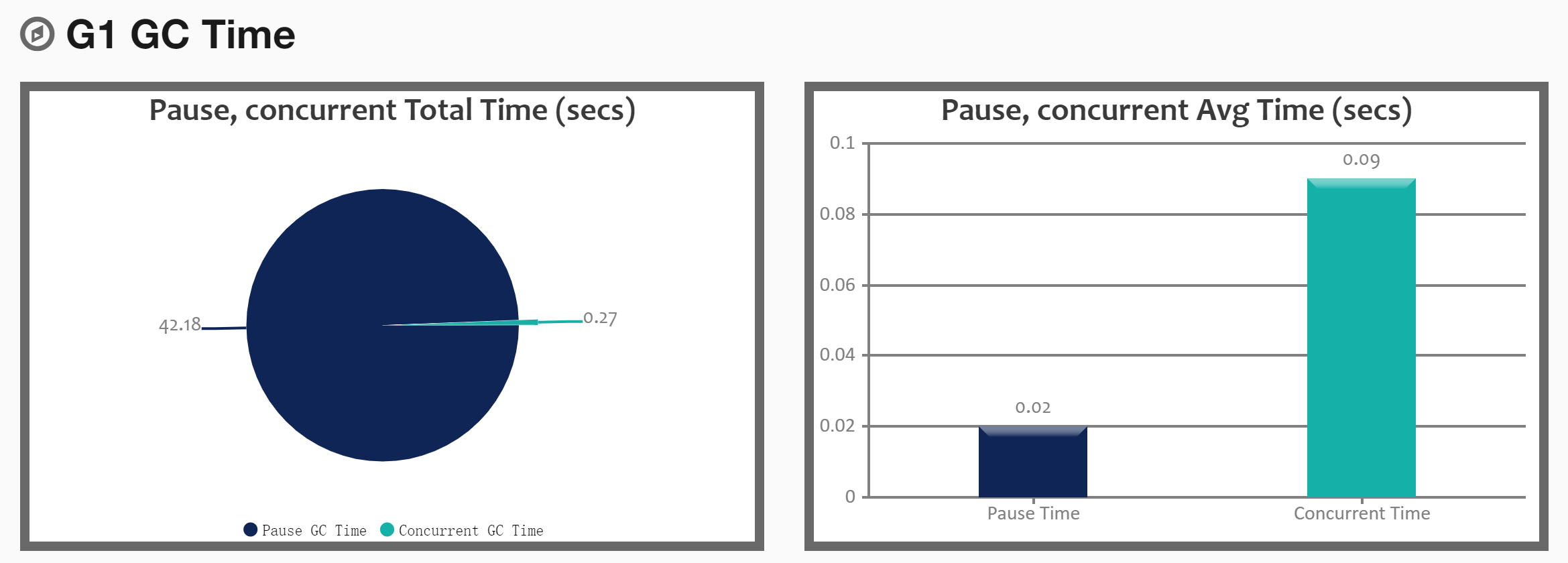
JAVA_OPT="${JAVA_OPT} -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps -XX:+PrintHeapAtGC -Xloggc:${BASE_DIR}/logs/gc-g-one.log"对于G1垃圾收集器参数设置建议:
- 设置为100-300之间比较合理,不要设置的太短
- 堆内存小于2GB,不建议使用G1
JVM调优实战场景
实战01-内存溢出的定位与分析
内存溢出在实际的生产环境中经常会遇到,比如,不断的将数据写入到一个集合中,出现了死循环,读取超大的文件等等,都可能会造成内存溢出。
如果出现了内存溢出,首先我们需要定位到发生内存溢出的环节,并且进行分析,是正常还是非正常情况,如果是正常的需求,就应该考虑加大内存的设置,如果是非正常需求,那么就要对代码进行修改,修复这个bug。
首先,我们得先学会如何定位问题,然后再进行分析。如何定位问题呢,我们需要借助于jmap与MAT工具进行定位分析。接下来,我们模拟内存溢出的场景。
模拟内存溢出
编写代码,向List集合中添加100万个字符串,每个字符串由1000个UUID组成。如果程序能够正常执行,最后打印ok。
package com.hero.jvm.memory;
import java.util.ArrayList;
import java.util.List;
import java.util.UUID;
public class TestJvmOutOfMemory {
public static void main(String[] args) {
List<Object> list = new ArrayList<>();
for (int i = 0; i < 10000000; i++) {
String str = "";
for (int j = 0; j < 1000; j++) {
str += UUID.randomUUID().toString();
}
list.add(str);
}
System.out.println("ok");
}
}为了演示效果,我们将设置执行的参数,这里使用的是Idea编辑器
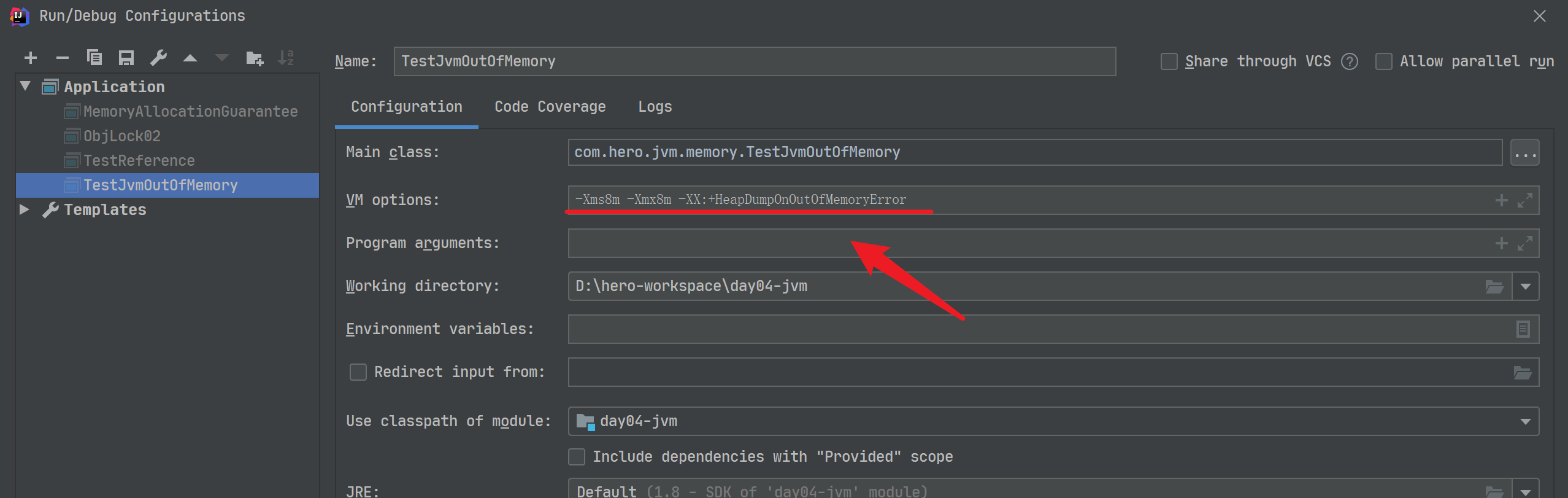
#参数如下:
-Xms8m -Xmx8m -XX:+HeapDumpOnOutOfMemoryError运行测试
测试结果如下:
java.lang.OutOfMemoryError: Java heap space
Dumping heap to java_pid31092.hprof ...
Heap dump file created [8453096 bytes in 0.031 secs]
Exception in thread "main" java.lang.OutOfMemoryError: Java heap space
at java.util.Arrays.copyOf(Arrays.java:3332)
at java.lang.AbstractStringBuilder.ensureCapacityInternal(AbstractStringBuilder.java:124)
at java.lang.AbstractStringBuilder.append(AbstractStringBuilder.java:448)
at java.lang.StringBuilder.append(StringBuilder.java:136)
at com.hero.TestJvmOutOfMemory.main(TestJvmOutOfMemory.java:13)可以看到,当发生内存溢出时,会dump文件到java_pid31092.hprof。
导入到MAT工具中进行分析
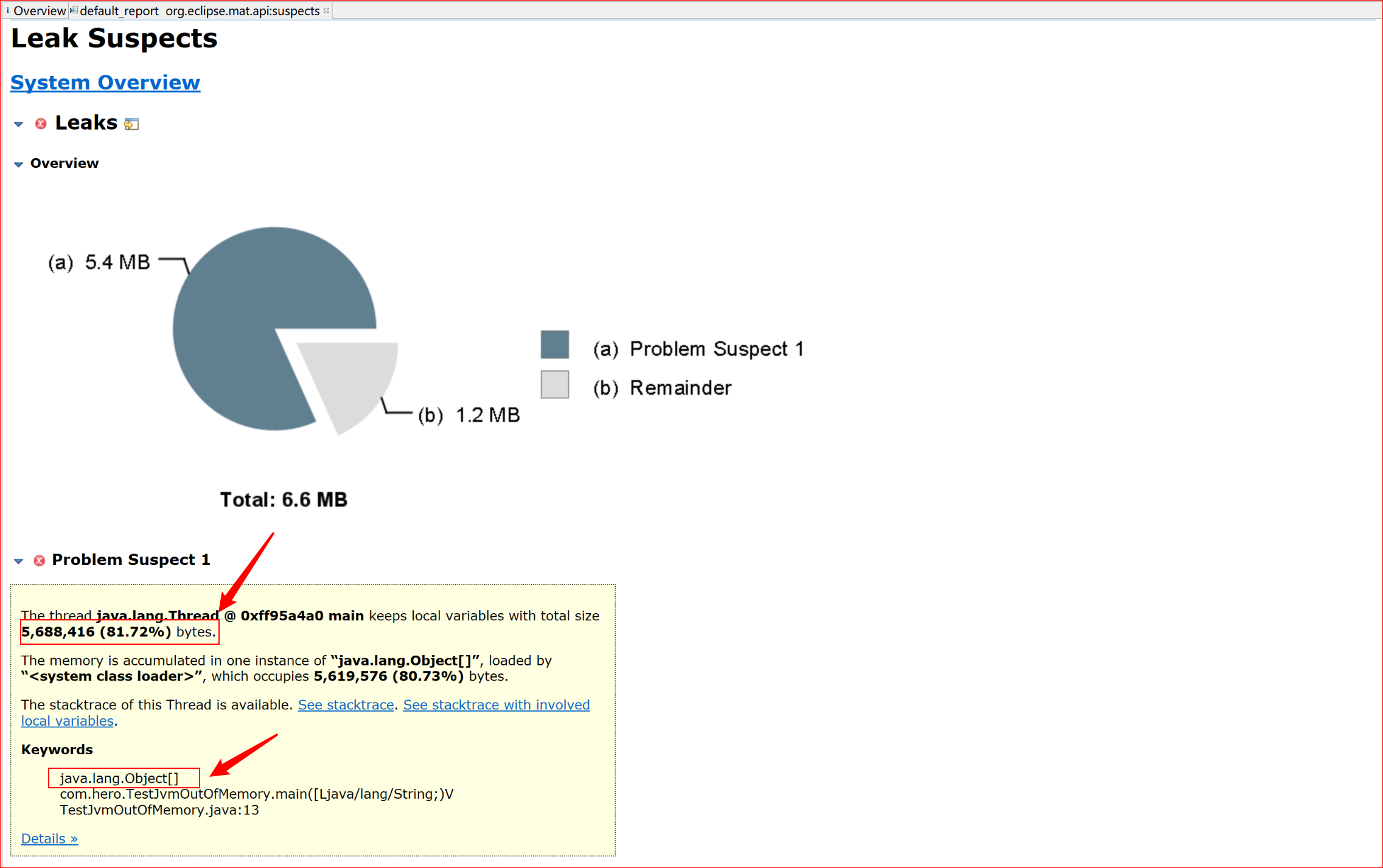
可以看到,有81.72%的内存由Object[]数组占有,所以比较可疑。
分析:这个可疑是正确的,因为已经有超过80%的内存都被它占有,这是非常有可能出现内存溢出的。
查看详情:
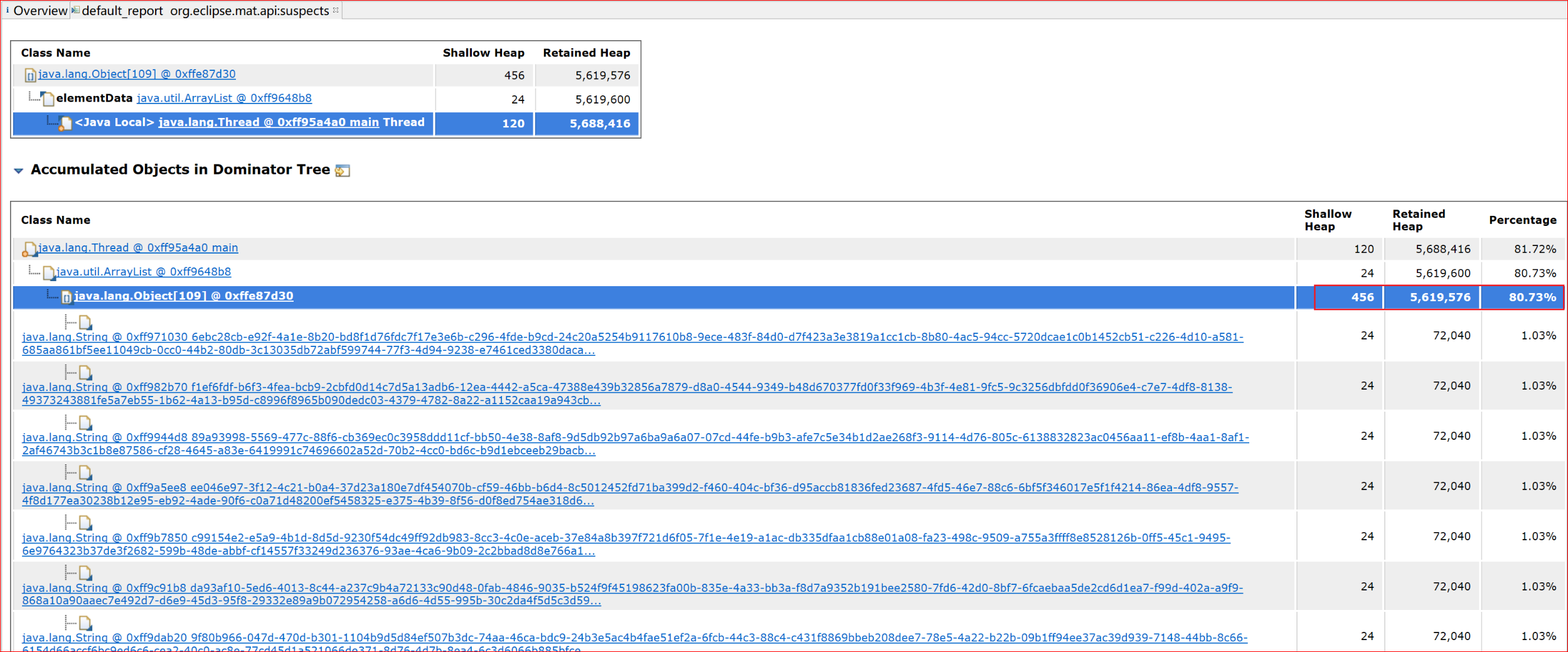
可以看到集合中存储了大量的uuid字符串。
实战02-检测死锁
有些时候我们需要查看下jvm中的线程执行情况,比如,发现服务器的CPU的负载突然增高了、出现了死锁、死循环等,我们该如何分析呢?
由于程序是正常运行的,没有任何的输出,从日志方面也看不出什么问题,所以就需要看下JVM的内部线程的执行情况,然后再进行分析查找出原因。
这个时候,就需要借助于jstack命令了,jstack的作用是将正在运行的jvm的线程情况进行快照,并且打印出来:
线程的状态
见并发编程
实战:死锁问题
如果在生产环境发生了死锁,我们将看到的是部署的程序没有任何反应了,这个时候我们可以借助jstack进行分析,下面我们实战下查找死锁的原因。
构造死锁
编写代码,启动2个线程,Thread1拿到了obj1锁,准备去拿obj2锁时,obj2已经被Thread2锁定,所以发生了死锁。
public class TestDeadLock {
private static Object obj1 = new Object();
private static Object obj2 = new Object();
public static void main(String[] args) {
new Thread(new Thread1()).start();//启动线程01
new Thread(new Thread2()).start();//启动线程02
}
//线程01
private static class Thread1 implements Runnable {
@Override
public void run() {
synchronized (obj1) {
System.out.println("Thread1 拿到了 obj1 的锁!");
try {
// 停顿2秒的意义在于,让Thread2线程拿到obj2的锁
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
synchronized (obj2) {
System.out.println("Thread1 拿到了 obj2 的锁!");
}
}
}
}
//线程02
private static class Thread2 implements Runnable {
@Override
public void run() {
synchronized (obj2) {
System.out.println("Thread2 拿到了 obj2 的锁!");
try {
// 停顿2秒的意义在于,让Thread1线程拿到obj1的锁
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
synchronized (obj1) {
System.out.println("Thread2 拿到了 obj1 的锁!");
}
}
}
}
}在Linux上运行

使用jstack进行分析
jstack 18487 | grep 'BLOCKED' -A 15 --color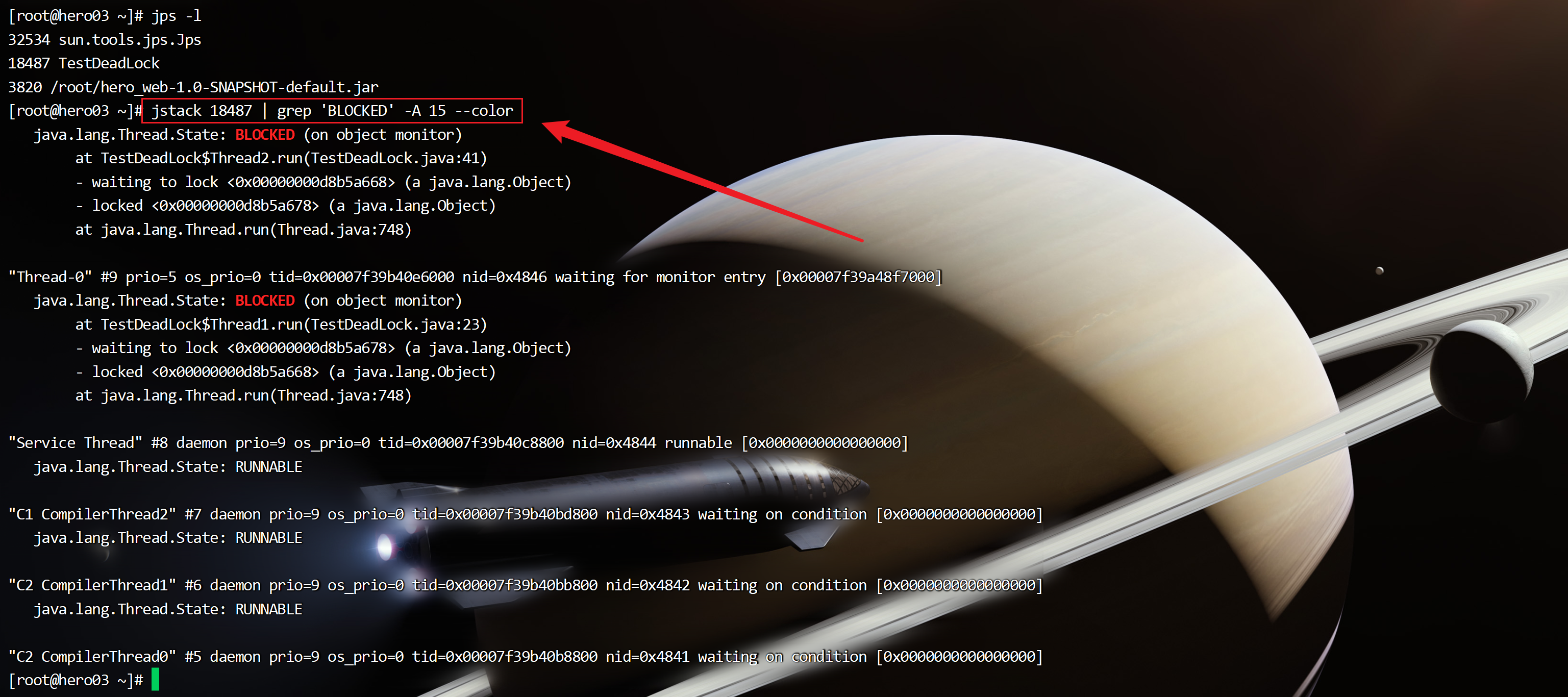
可以清晰的看到:
Thread2获取了 <0x00000000d8b5a678> 的锁,等待获取 <0x00000000d8b5a668>这个锁
Thread1获取了 <0x00000000d8b5a668> 的锁,等待获取 <0x00000000d8b5a678>这个锁
由此可见,发生了死锁。使用Arthas进行分析
thread -b
可以准确知道: 死锁在代码的中的第几行
扩展01-高并发场景下JVM调优实践
背景:不久之前,我解决了这样一个JVM性能问题。我司APP某核心接口高峰期响应慢。通过Grafana发现,接口响应慢、同时该服务的GC也有异常,两者之间存在相关性。本案例是来自于当时的实践。
