6.线程池
6.1 线程池介绍
线程池(ThreadPool) 是一种基于池化思想管理线程的工具,看过new Thread源码之后我们发现,频繁创建线程销毁线程的开销很大,会降低系统整体性能。线程池维护多个线程,等待监督和管理分配可并发执行的任务。
优点:
降低资源消耗:通过线程池复用线程,降低创建线程和释放线程的损耗
提高响应速度:任务到达时,无需等待即刻运行
提高线程的可管理性:使用线程池可以进行统一的分片、调优和监控线程
提供可扩展性:线程池具备可扩展性,研发人员可以向其中增加各种功能,比如延时,定时,监控等
适用场景:
连接池:预先申请数据库连接,提升申请连接的速度,降低系统的开销
快速响应用户请求:服务器接受到大量请求时,使用线程池是很适合的,它可以大大减少线程的创建和销毁的次数,提高服务器的工作效率。
在实际开发中,如果需要创建5个以上的线程,就可以用线程池来管理。
6.2 线程池参数
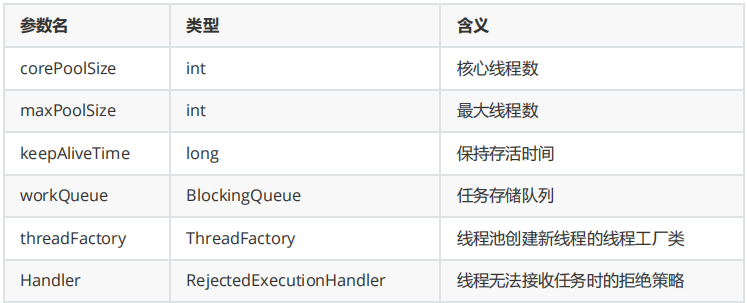
参数详解:
corePoolSize核心线程数:即便线程空闲(Idle)也不会回收
maxPoolSize最大线程数:线程池可能会在核心线程数的基础上,额外增加一些线程,但是这些新增加的线程数有一个上限,就是maxPoolSize
ThreadFactory新的线程是由ThreadFactory创建,默认使用Executors.defaultThreadFactory(),创建出来的线程都在同一个线程组,拥有同样的NORM_PRIORITY优先级并且都不是守护线程。如果自己指定ThreadFactory,则可以改变线程名、线程组、优先级、是否是守护线程
workQueue工作队列类型
直接交换:SynchronousQueue,这个队列没有容量,无法保存工作任务。
无界队列:LinkedBlockingQueue无界队列
有界队列:ArrayBlockingQueue有界队列
6.3 线程池原理
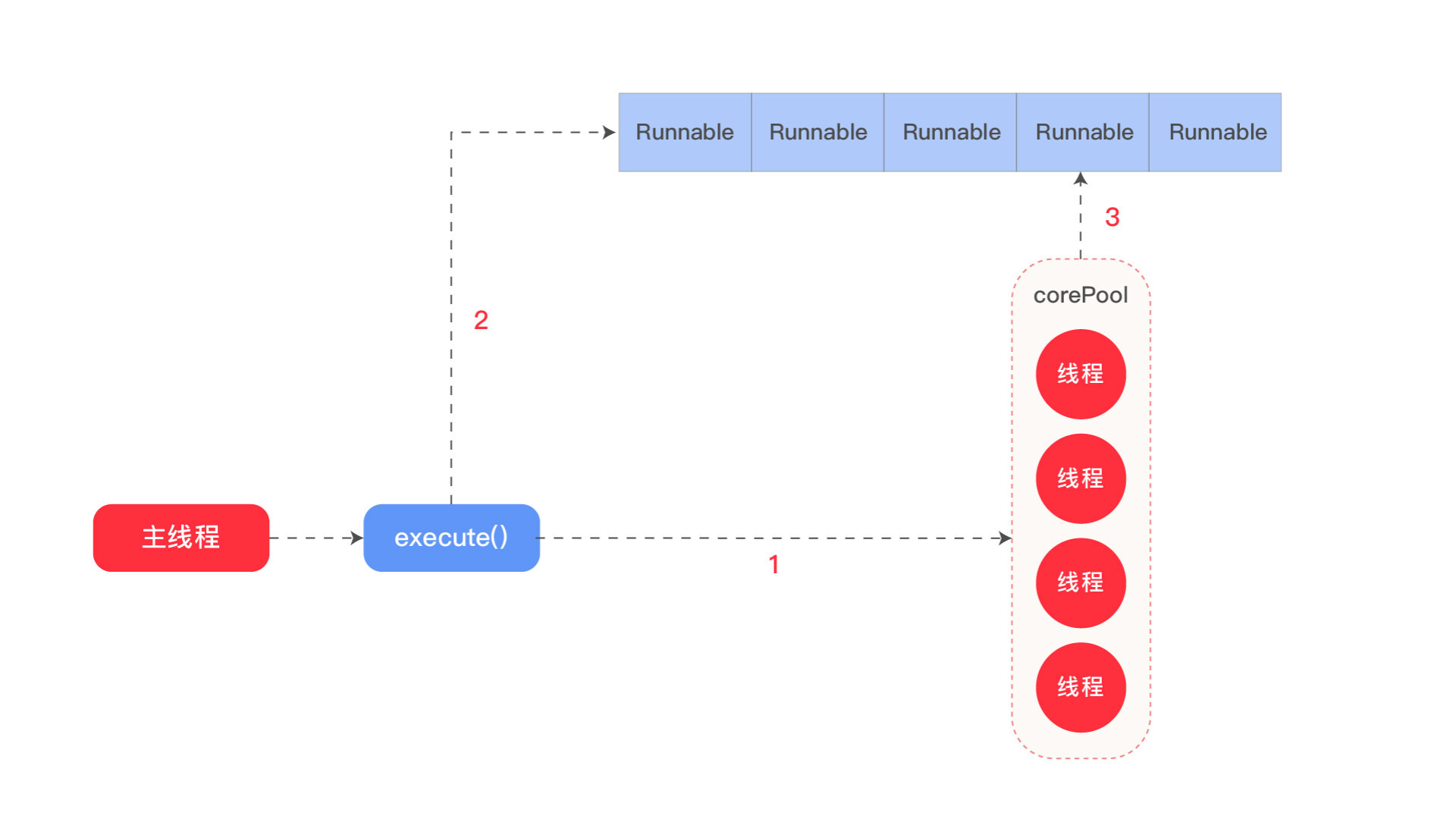
如果线程数小于corePoolSize,即使其它工作线程处于空闲状态,也会创建一个新线程来运行新任务。
如果线程数大于等于corePoolSize,但少于maxPoolSize,将任务放入队列。
如果队列已满,并且线程数小于maxPoolSize,则创建一个新线程来运行任务。
如果队列已满,并且线程数大于或等于maxPoolSize,则拒绝该任务。
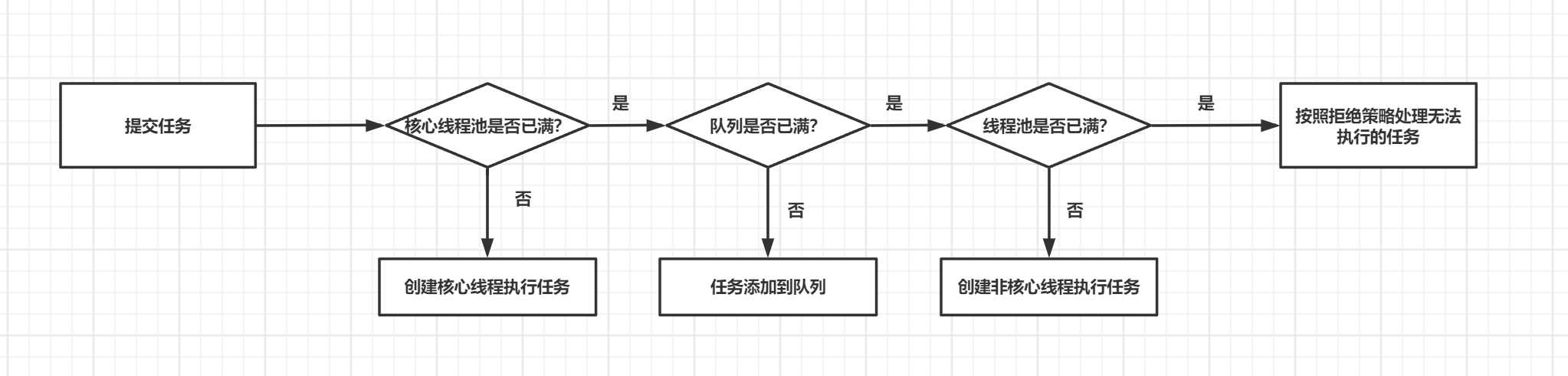
例子:核心池大小为5,最大池大小为10,队列为100
因为线程中的请求最多会创建5个,然后任务将被添加到队列中,直到达到100。
当队列已满时,将创建最新的线程maxPoolSize,最多到10个线程,如果再来任务,则拒绝。
增减线程的特点
固定大小线程池:通过设置corePoolSize和maxPoolSize相同,可以创建固定大小的线程池。
动态线程池:线程池希望保持较少的线程数,并且只有在负载变得很大时才会增加。可以设置corePoolSize比maxPoolSize大一些
通过设置maxPoolSize为很高的值,例如Integer.MAX_VALUE,可以允许线程池容纳任意数量的并发任务。
只有在队列填满时才创建多于corePoolSize的线程,所以如果用的是无界队列(LinkedBlockingQueue),则线程数就一直不会超过corePoolSize
6.4 自动创建线程池
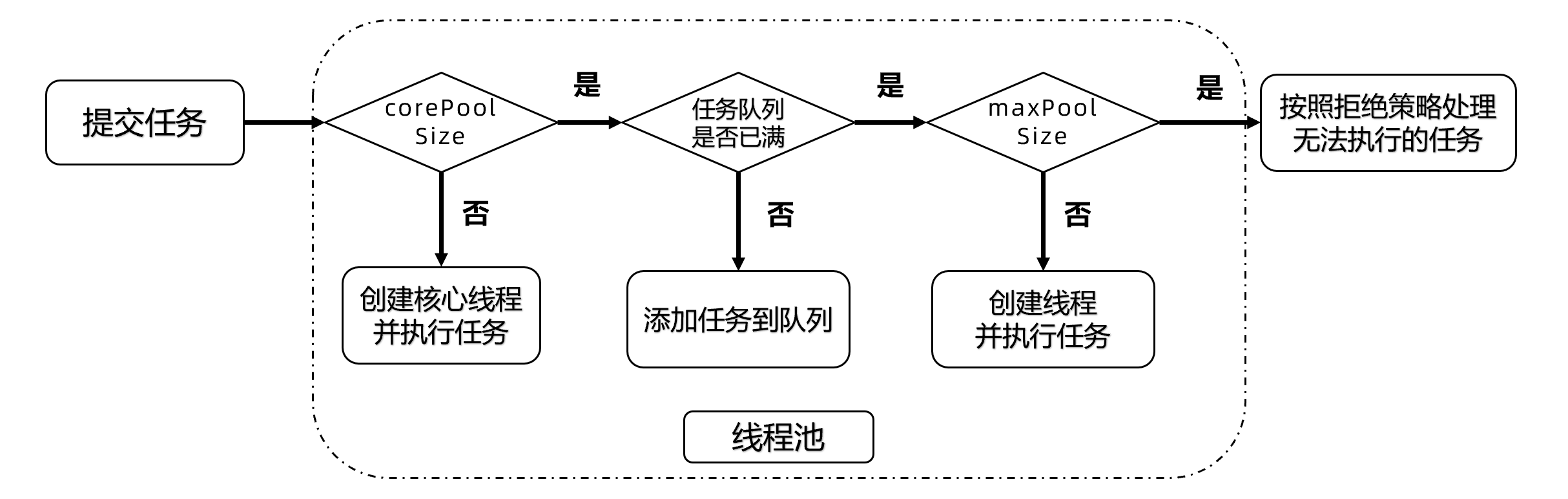
newFixedThreadPool
手动创建更好,因为这样可以更明确线程池的运行规则,避免资源耗尽的风险。
package com.hero.multithreading;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
/**
* 案例:演示newFixedThreadPool
*/
public class Demo17FixedThreadPool {
public static void main(String[] args) {
ExecutorService executorService = Executors.newFixedThreadPool(4);
for (int i = 0; i < 1000; i++) {
executorService.execute(new Task());
}
}
}
class Task implements Runnable {
@Override
public void run() {
try {
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName());
}
}不管有多少任务,始终只有4个线程在执行。
源码解读
public static ExecutorService newFixedThreadPool(int nThreads) {
//nThreads
//nThreads
//0L
//TimeUnit.MILLISECONDS
//new LinkedBlockingQueue<Runnable>()
return new ThreadPoolExecutor(nThreads, nThreads,0L, TimeUnit.MILLISECONDS,new LinkedBlockingQueue<Runnable>());
}参数01是核心线程数量
参数02是最大线程数量,它设置的与核心线程数量一样,不会有超过核心线程数量的线程出现,所以第三个参数存活时间设置为0,
参数04是无界队列,有再多的任务也都会放在队列中,不会创建新的线程。
如果线程处理任务的速度慢,越来越多的任务就会放在无界队列中,会占用大量内存,这样就会导致内存溢出(OOM)的错误。
package com.hero.multithreading;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
/**
* 案例:演示newFixedThreadPool出错的情况
* -Xmx8m -Xms8m
*/
public class Demo18FixedThreadPoolOOM {
private static ExecutorService executorService = Executors.newFixedThreadPool(1);
public static void main(String[] args) {
for (int i = 0; i < Integer.MAX_VALUE; i++) {
executorService.execute(new SubThread());
}
}
}
class SubThread implements Runnable {
@Override
public void run() {
try {
//处理越慢越好,演示内存溢出
Thread.sleep(1000000000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}newSingleThreadExecutor
只有一个线程
package com.hero.multithreading;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class Demo19SingleThreadExecutor {
public static void main(String[] args) {
ExecutorService executorService = Executors.newSingleThreadExecutor();
for (int i = 0; i < 1000; i++) {
executorService.execute(new Task());
}
}
}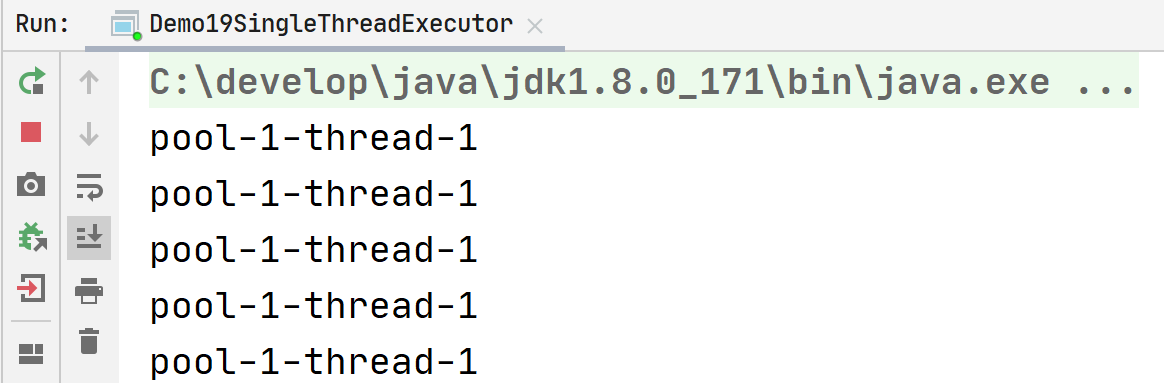
它和newFixedThreadPool的原理相同,只不过把线程数直接设置为1,当请求堆积时,也会占用大量内存。
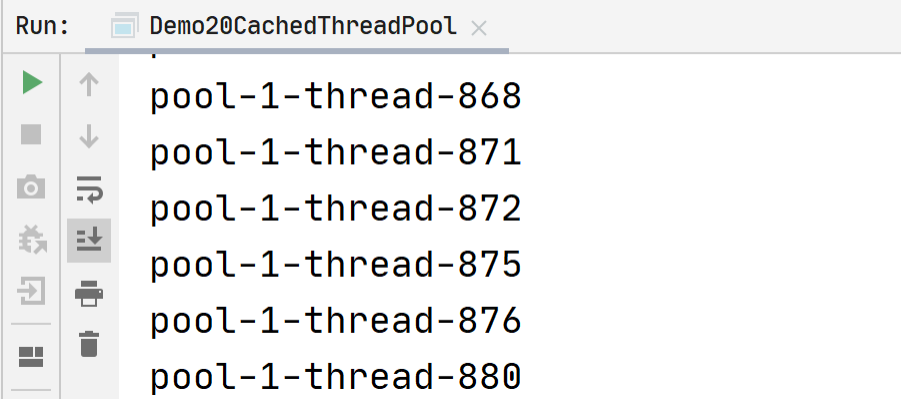
newCachedThreadPool
可缓存线程池,它是无界线程池,并具有自动回收多余线程的功能。
package com.hero.multithreading;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
/**
* 案例:演示CachedThreadPool
*/
public class Demo20CachedThreadPool {
public static void main(String[] args) {
ExecutorService executorService = Executors.newCachedThreadPool();
for (int i = 0; i < 1000; i++) {
executorService.execute(new Task());
}
}
}
源码解读
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,60L, TimeUnit.SECONDS,new SynchronousQueue<Runnable>());
}参数01是核心线程数,为0
参数02线程池的最大线程数量是整数的最大值,可以认为没有上限,有多个任务过来就创建多个线程去执行。
参数03一定时间后(默认60秒),会将多余的线程进行回收。
参数04SynchronousQueue是直接交换队列,容量为0,所以不能将任务放在队列中。任务过来后直接交给线程去执行。
弊端:第二个参数maxPoolSize设置为Integer.MAX_VALUE,可能会创建非常多的线程,导致OOM
newScheduledThreadPool
支持定时及周期性任务执行的线程池
package com.hero.multithreading;
import java.util.concurrent.Executors;
import java.util.concurrent.ScheduledExecutorService;
import java.util.concurrent.TimeUnit;
/**
* 案例:演示newScheduledThreadPool
*/
public class Demo21ScheduledThreadPool {
public static void main(String[] args) {
ScheduledExecutorService threadPool = Executors.newScheduledThreadPool(10);
//延迟5秒运行
//threadPool.schedule(new Task(), 5, TimeUnit.SECONDS);
//先延迟1秒运行,然后每隔3秒运行一次
threadPool.scheduleAtFixedRate(new Task(), 1, 3,TimeUnit.SECONDS);
}
}6.5 手动创建线程池
部分企业的开发规范中会禁止使用快捷线程池,要求通过标准构造器 ThreadPoolExecutor 去构造工作线程池。
// 使用标准构造器,构造一个普通的线程池
public ThreadPoolExecutor(
int corePoolSize, // 核心线程数,即使线程空闲(Idle),也不会回收;
int maximumPoolSize, // 线程数的上限;
long keepAliveTime, TimeUnit unit, // 线程最大空闲(Idle)时长
BlockingQueue workQueue, // 任务的排队队列
ThreadFactory threadFactory, // 新线程的产生方式
RejectedExecutionHandler handler) // 拒绝策略根据不同的业务场景,自己设置线程池的参数、线程名、任务被拒绝后如何记录日志等。
设置线程池数量
- CPU密集型线程池:CPU 密集型任务也叫计算密集型任务,其特点是要进行大量计算而需要消耗CPU 资源,比如计算圆周率、对视频进行高清解码等等。 CPU 密集型任务虽然也可以并行完成,但是并行的任务越多,花在任务切换的时间就越多, CPU 执行任务的效率就越低,所以,要最高效地利用 CPU,CPU 密集型任务的并行执行的数量应当等于 CPU 的核心数。
- IO密集型线程池:由于 IO 密集型任务的 CPU 使用率较低,导致线程空余时间很多,所以通常就需要开 CPU核心数两倍的线程。当 IO 线程空闲时,可以启用其他线程继续使用 CPU,以提高 CPU的使用率。
拒绝策略
拒绝时机
当Executor关闭时,提交新任务会被拒绝。
当Executor对最大线程和工作队列容量使用有限边界并且已经饱和时
AbortPolicy:直接抛出异常,说明任务没有提交成功
DiscardPolicy:线程池会默默的丢弃任务,不会发出通知
DiscardOldestPolicy:队列中存有很多任务,将队列中存在时间最久的任务给丢弃。
CallerRunsPolicy:当线程池无法处理任务时,那个线程提交任务由那个线程负责运行。好处在于避免丢弃任务和降低提交任务的速度,给线程池一个缓冲时间。
6.6 线程池案例:手写网站服务器案例
需求:模拟基于Http协议的网站服务器,使用浏览器访问自己编写的服务端程序。然后压测看一看
案例分析:
准备测试页面及图片,存放在web文件夹
模拟服务器端(ServerSocket)使用浏览器访问,查看页面效果
本案例涉及并发编程与网络编程,我们先来观察并发编程部分
/**
* 线程池版本
*/
public class BsServer03 {
public static void main(String[] args) throws IOException {
System.out.println("服务器 启动..... ");
System.out.println("开启端口 : 9999..... ");
// 创建服务端ServerSocket
ServerSocket serverSocket = new ServerSocket(9999);
//创建10个线程的线程池
ExecutorService executorService = Executors.newFixedThreadPool(10);
while (true) {
Socket accept = serverSocket.accept();
//提交线程执行的任务
executorService.submit(()->{
try{
/*
*socket对象进行读写操作
*/
//转换流,读取浏览器请求第一行
BufferedReader readWb = new BufferedReader(new
InputStreamReader(accept.getInputStream()));
String requst = readWb.readLine();
//取出请求资源的路径
String[] strArr = requst.split(" ");
System.out.println(Arrays.toString(strArr));
String path = strArr[1].substring(1);
System.out.println(path);
//----
FileInputStream fis = new FileInputStream(path);
System.out.println(fis);
byte[] bytes= new byte[1024];
int len = 0 ;
//向浏览器 回写数据
OutputStream out = accept.getOutputStream();
out.write("HTTP/1.1 200 OK\r\n".getBytes());
out.write("Content-Type:text/html\r\n".getBytes());
out.write("\r\n".getBytes());
while((len = fis.read(bytes))!=-1){
out.write(bytes,0,len);
}
fis.close();
out.close();
readWb.close();
accept.close();
} catch (IOException e) {
e.printStackTrace();
}
});
}
}
}7.ThreadLocal
说一下ThreadLocalMap的key为什么是弱类型?使用完ThreadLocal为什么必须要remove?
7.1 什么是ThreadLocal?
ThreadLocal 被译为“线程本地变量”类,在 Java 的多线程并发执行过程中,为保证多个线程对变量的安全访问,可以将变量放到ThreadLocal 类型的对象中,使变量在每个线程中都有独立值,不会出现一个线程读取变量时而被另一个线程修改的现象。
ThreadLocal 是解决线程安全问题一个较好方案,它通过为每个线程提供一个独立的本地值,去解决并发访问的冲突问题。很多情况下,使用 ThreadLocal 比直接使用同步机制(如 synchronized)解决线程安全问题更简单,更方便,且结果程序拥有更高的并发性。
举例:
- ThreadLocal在Spring中作用巨大,在管理Request作用域中的Bean、事务、任务调度、AOP等模块都有它。
- Spring中绝大部分Bean都可以声明成Singleton作用域,采用ThreadLocal进行封装,因此有状态的Bean就能够以singleton的方式在多线程中正常工作了。
7.2 ThreadLocal 使用场景
ThreadLocal 使用场景大致可以分为以下两类:
1.解决线程安全问题
ThreadLocal 的主要价值在于解决线程安全问题, ThreadLocal 中数据只属于当前线程,其本地值对别的线程是不可见的,在多线程环境下,可以防止自己的变量被其他线程篡改。另外,由于各个线程之间的数据相互隔离,避免同步加锁带来的性能损失,大大提升了并发性的性能。
典型案例:可以每个线程绑定一个数据库连接,是的这个数据库连接为线程所独享,从而避免数据库连接被混用而导致操作异常问题。
//伪代码
private static final ThreadLocal localSqlSession = new ThreadLocal();
public void startManagedSession() {
this.localSqlSession.set(openSession());
}
@Override
public Connection getConnection() {
final SqlSession sqlSession = localSqlSession.get();
if (sqlSession == null) {
throw new SqlSessionException("Error: Cannot get connection. No managed session is started.");
}
return sqlSession.getConnection();
}2.跨函数传递数据
通常用于同一个线程内,跨类、跨方法传递数据时,如果不用 ThreadLocal,那么相互之间的数据传递势必要靠返回值和参数,这样无形之中增加了这些类或者方法之间的耦合度。
“跨函数传递数据”场景典型案例:可以每个线程绑定一个 Session(用户会话)信息,这样一个线程的所有调用到的代码,都可以非常方便地访问这个本地会话,而不需要通过参数传递。
//伪代码
public class SessionHolder{
// 用户信息 线程本地变量
private static final ThreadLocal<UserDTO> sessionUserLocal = new ThreadLocal<>("sessionUserLocal");
// session 线程本地变量
private static final ThreadLocal<HttpSession> sessionLocal = new ThreadLocal<>("sessionLocal");
//...省略其他
/**
*保存 session 在线程本地变量中
*/
public static void setSession(HttpSession session){
sessionLocal.set(session);
}
/**
* 取得绑定在线程本地变量中的 session
*/
public static HttpSession getSession() {
HttpSession session = sessionLocal.get();
Assert.notNull(session, "session 未设置");
return session;
}
//...省略其他
}7.3 底层原理
ThreadLocal内部结构演进:
早期ThreadLocal为一个 Map。当工作线程 Thread 实例向本地变量保持某个值时,会以“Key-Value 对”的形式保存在 ThreadLocal 内部的 Map 中,其中 Key为线程 Thread 实例, Value 为待保存的值。当工作线程 Thread 实例从 ThreadLocal 本地变量取值时,会以 Thread 实例为 Key,获取其绑定的Value。
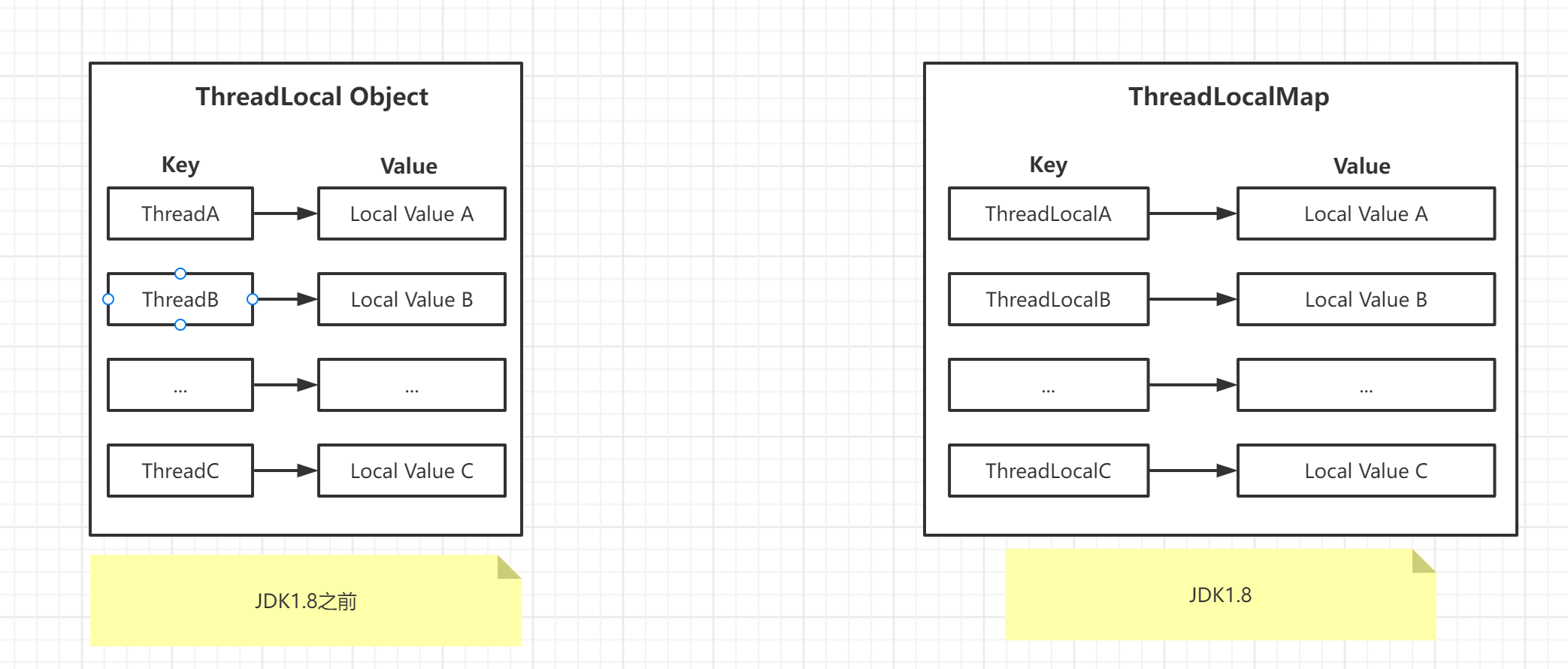
在 JDK8 版本中, ThreadLocal 的内部结构依然是Map结构,但是其拥有者为Thread线程对象,每一个Thread 实例拥有一个ThreadLocalMap对象。Key 为 ThreadLocal 实例。
与早期版本的 ThreadLocalMap 实现相比,新版本的主要的变化为:
- 拥有者发生了变化:新版本的 ThreadLocalMap 拥有者为 Thread,早期版本的ThreadLocalMap拥有者为 ThreadLocal。
- Key 发生了变化:新版本的 Key 为 ThreadLocal 实例,早期版本的 Key 为 Thread 实例。
与早期版本的 ThreadLocalMap 实现相比,新版本的主要优势为:
ThreadLocalMap 存储的“Key-Value 对”数量变少
Thread 实例销毁后, ThreadLocalMap 也会随之销毁,在一定程度上能减少内存的消耗。
Thread、ThreadLocal、ThreadLocalMap关系
Thread --> ThreadLocalMap --> Entry(ThreadLocalN, LocalValueN)*n7.4 Entry 的 Key 为什么需要使用弱引用?
Entry 用于保存 ThreadLocalMap 的“Key-Value”条目,但是 Entry 使用了对 Threadlocal 实例进行包装之后的弱引用(WeakReference)作为 Key,其代码如下:
// Entry 继承了 WeakReference,并使用 WeakReference 对 Key 进行包装
static class Entry extends WeakReference<ThreadLocal<?>> {
Object value; //值
Entry(ThreadLocal<?> k, Object v) {
super(k); //使用 WeakReference 对 Key 值进行包装
value = v;
}
}为什么 Entry 需要使用弱引用对 Key 进行包装,而不是直接使用 Threadlocal 实例作为 Key呢?比如如下代码
//伪代码
public void funcA() {
//创建一个线程本地变量
ThreadLocal local = new ThreadLocal();
//设置值
local.set(100);
//获取值
local.get();
//函数末尾
}当线程n 执行 funcA 方法到其末尾时,线程n 相关的 JVM 栈内存以及内部 ThreadLocalMap成员的结构,大致如图所示。
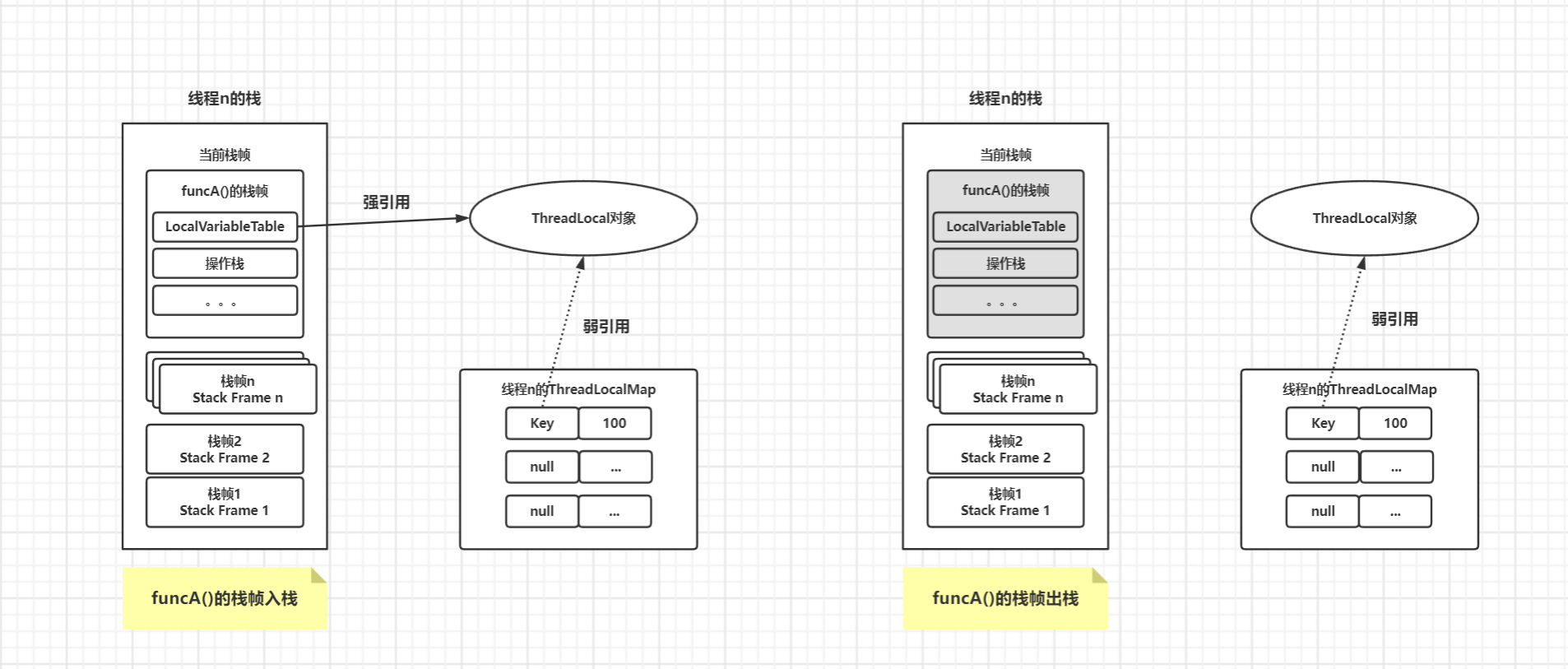
线程n 调用 funcA()方法新建了一个 ThreadLocal 实例,并使用 local 局部变量指向这个实例,并且此 local 是强引用;
在调用 local .set(100)之后,线程n 的 ThreadLocalMap 成员内部会新建一个 Entry 实例,其 Key 以弱引用包装的方式指向 ThreadLocal 实例。
当线程n 执行完 funcA 方法后, funcA 的方法栈帧将被销毁,强引用 local 的值也就没有了,但此时线程的 ThreadLocalMap 里的对应的 Entry 的 Key 引用还指向了 ThreadLocal 实例。
若 Entry的 Key 引用是强引用,就会导致 Key 引用指向的 ThreadLocal 实例、及其 Value 值都不能被GC回收,这将造成严重的内存泄露,具体如图所示。
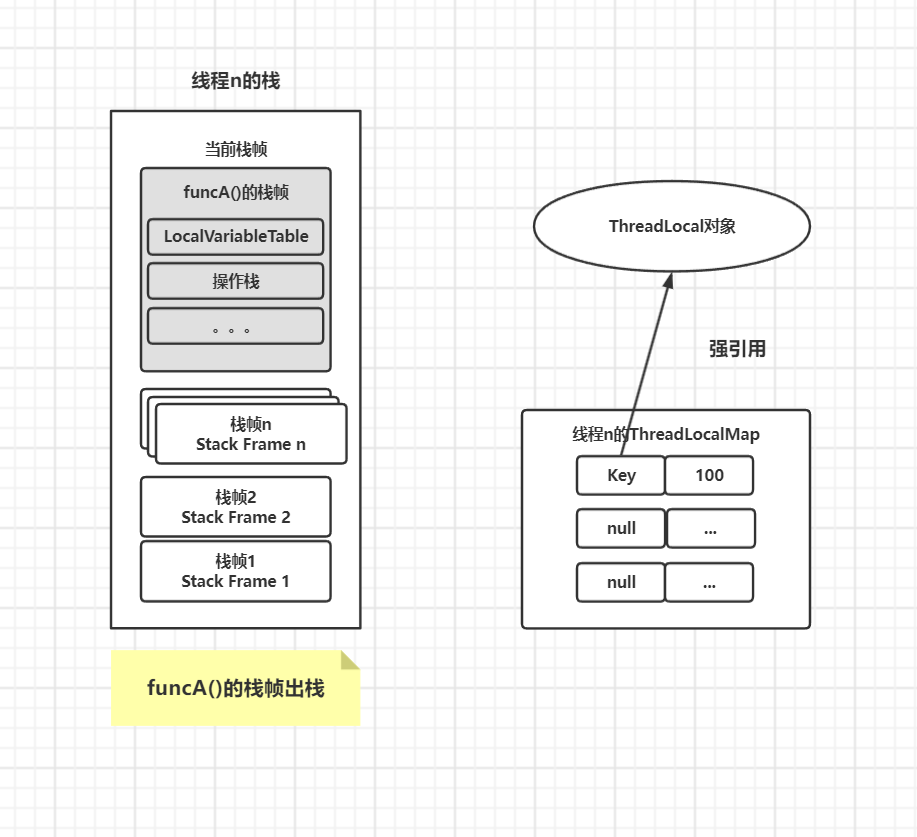
由于 ThreadLocalMap 中 Entry 的 Key 使用了弱引用,在下次 GC 发生时,就可以使那些没有被其他强引用指向、仅被 Entry 的 Key 所指向的 ThreadLocal 实例能被顺利回收。并且,在 Entry的 Key 引用被回收之后,其 Entry 的 Key 值变为 null。后续当 ThreadLocal 的 get、 set 或 remove 被调用时,通过expungeStaleEntry方法, ThreadLocalMap 的内部代码会清除这些 Key 为 null 的 Entry,从而完成相应的内存释放。
8. Future和FutureTask
8.1 Future类
FutureTask叫未来任务,可以将一个复杂的任务剔除出去交给另外一个线程来完成
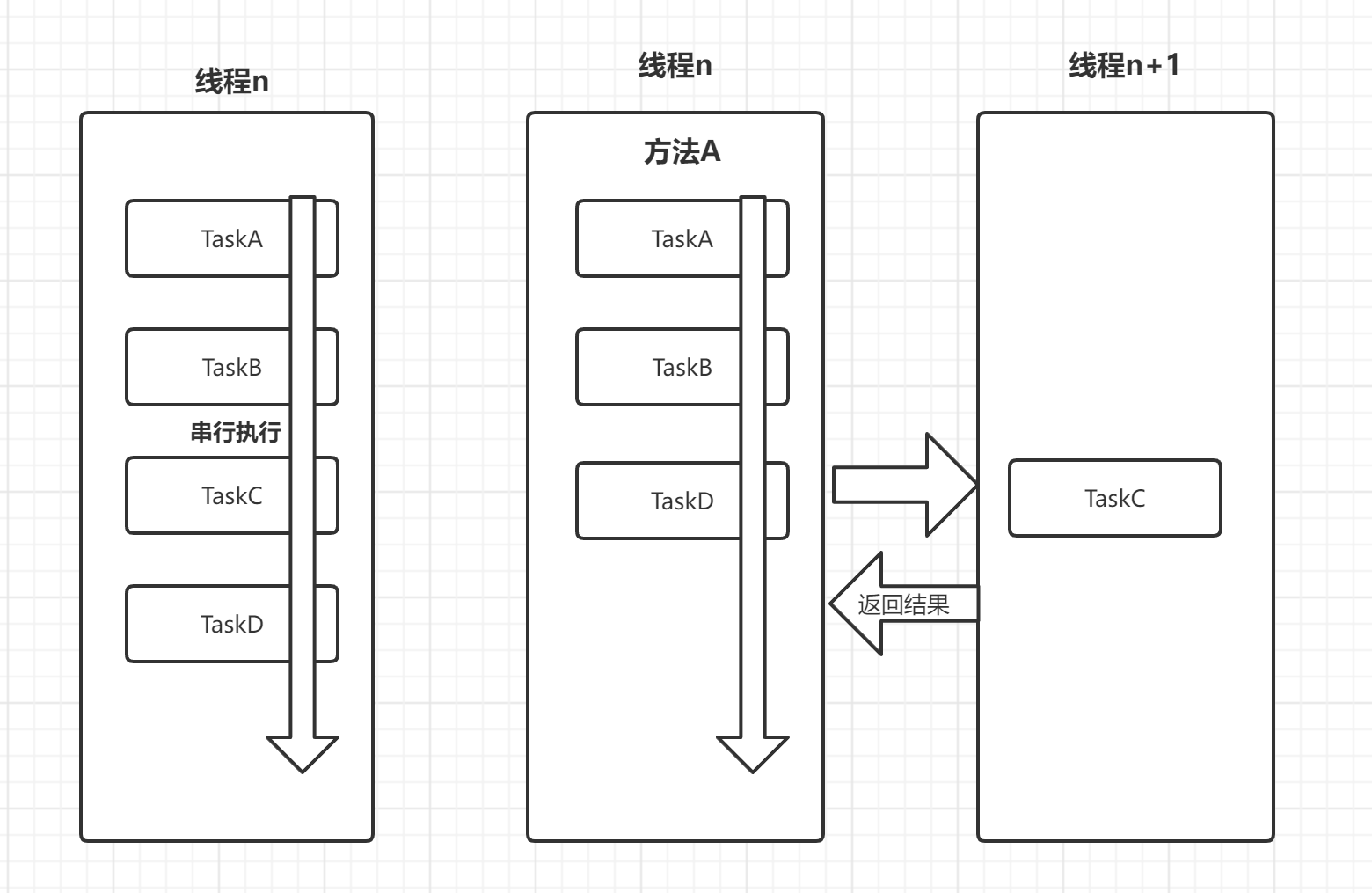
图示为main方法开始,依次调用多个方法。但是第3个方法复杂,为避免其是瓶颈影响整个程序效率,所以将其剔除出去交给FutureTask去完成,这样避免阻塞主线程。
8.2 Future主要方法
get()
get方法的行为取决于Callable任务的状态,只有以下5种情况:
任务正常完成:get方法会立刻返回结果
任务尚未完成:任务还没有开始或进行中,get将阻塞并直到任务完成。
任务执行过程中抛出Exception:get方法会抛出ExecutionException,这里抛出异常,是call()执行时产生的那个异常
任务被取消:get方法会抛出CancellationException
任务超时:get方法有一个重写方法,是传入一个延迟时间的,如果时间到了还没有获得结果,get方法会抛出TimeoutException
get(long timeout,TimeUnit unit)
如果call()在规定时间内完成任务,那么就会正常获取到返回值,而如果在指定时间内没有计算出结果,则会抛出TimeoutException
cancel()
如果这个任务还没有开始执行,任务会被正常取消,未来也不会被执行,返回true
如果任务已经完成或已经取消,则cancel()方法会执行失败,方法返回false
如果这个任务已经开始,这个取消方法将不会直接取消该任务,而是会根据参数mayInterruptIfRunningg来做判断。如果是true,就会发出中断信号给这个任务。
isDone()
- 判断线程是否执行完,执行完并不代表执行成功。
isCancelled()
- 判断是否被取消
8.3 用线程池的submit方法返回Future对象
首先要给线程池提交任务,提交时线程池会立刻返回一个空的Future容器。当线程的任务一旦执行完,也就是当我们可以获取结果时,线程池会把该结果填入到之前给我们的那个Future中去(而不是创建一个新的Future),我们此时可以从该Future中获得任务执行的结果。
package com.hero.multithreading;
import java.util.Random;
import java.util.concurrent.*;
/**
* 案例:演示一个Future的使用方法
*/
public class Demo22Future {
public static void main(String[] args) {
ExecutorService service = Executors.newFixedThreadPool(10);
Future<Integer> future = service.submit(new CallableTask());
try {
//等待3秒后打印
System.out.println(future.get());
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
}
service.shutdown();
}
static class CallableTask implements Callable<Integer> {
@Override
public Integer call() throws Exception {
Thread.sleep(3000);
return new Random().nextInt();
}
}
}8.5 用FutureTask来创建Future
用FutureTask来获取Future和任务的结果。FutureTask实现Runnable和Future接口
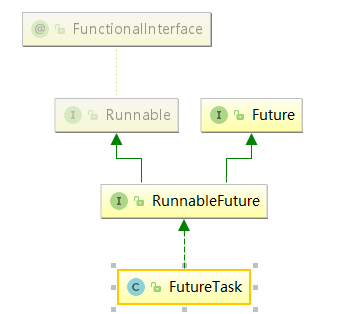
把Callable实例当作参数,生成FutureTask的对象,然后把这个对象当作一个Runnable对象,用线程池去执行这个Runnable对象,最后通过FutureTask获取刚才执行的结果。
package future;
import java.util.concurrent.Callable;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.FutureTask;
/**
* 描述:演示FutureTask的用法
*/
public class Demo23FutureTask {
public static void main(String[] args) {
Task task = new Task();
//FutureTask继承Future和Runnalbe接口
FutureTask<Integer> integerFutureTask = new FutureTask<>(task);
// new Thread(integerFutureTask).start();
ExecutorService service = Executors.newCachedThreadPool();
service.submit(integerFutureTask);
try {
System.out.println("task运行结果:"+integerFutureTask.get());
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
}
}
class Task implements Callable<Integer> {
@Override
public Integer call() throws Exception {
System.out.println("子线程正在计算");
Thread.sleep(3000);
//模拟子线程处理业务逻辑
int sum = 0;
for (int i = 0; i < 100; i++) {
sum += i;
}
return sum;
}
}扩展01-锁升级
多线程锁的升级原理是什么?
在Java中,synchronized共有4种状态,级别从低到高依次为:无状态锁,偏向锁,轻量级锁和重量级锁状态,这几个状态会随着竞争情况逐渐升级,锁可以升级但不能降级。
偏向锁:是指当一段同步代码一直被同一个线程所访问时,即不存在多个线程的竞争时,那么该线程在后续访问时便会自动获得锁,从而降低获取锁带来的消耗,即提高性能。
轻量级锁:(自旋锁)是指当锁是偏向锁的时候,却被另外的线程所访问,此时偏向锁就会升级为轻量级锁,其他线程会通过自旋的形式尝试获取锁,线程同样不会阻塞。长时间的自旋操作是非常消耗资源的,一个线程持有锁,其他线程就只能在原地空耗CPU,执行不了任何有效的任务,这种现象叫做忙等(busy-waiting)
重量级锁:此忙等是有限度的。如果锁竞争情况严重,某个达到最大自旋次数的线程,会将轻量级锁升级为重量级锁。当后续线程尝试获取锁时,发现被占用的锁是重量级锁,则直接将自己挂起(而不是忙等),等待将来被唤醒。,有个计数器记录自旋次数,默认允许循环10次,可以通过虚拟机参数更改
